This post seeks to give an overview of the research in this field and explain the difference between frozen, advanced, and fully dynamic RAG.
This article draws inspiration from the excellent lecture "Stanford CS25: V3 I Retrieval Augmented Language Models" by Douwe Kiela, who, along with Patrick Lewis, Ethan Perez, et al., invented RAG in May 2020.
The idea of enabling computers to extract information from a knowledge base to assist in language tasks goes back decades, with early question-answering systems from the 1960s and IBM's Watson Jeopardy system having similar conceptual underpinnings. To understand the origins of the first RAG-like systems in 2017 and its invention in 2021 we have to understand the underlying retrieval technology.
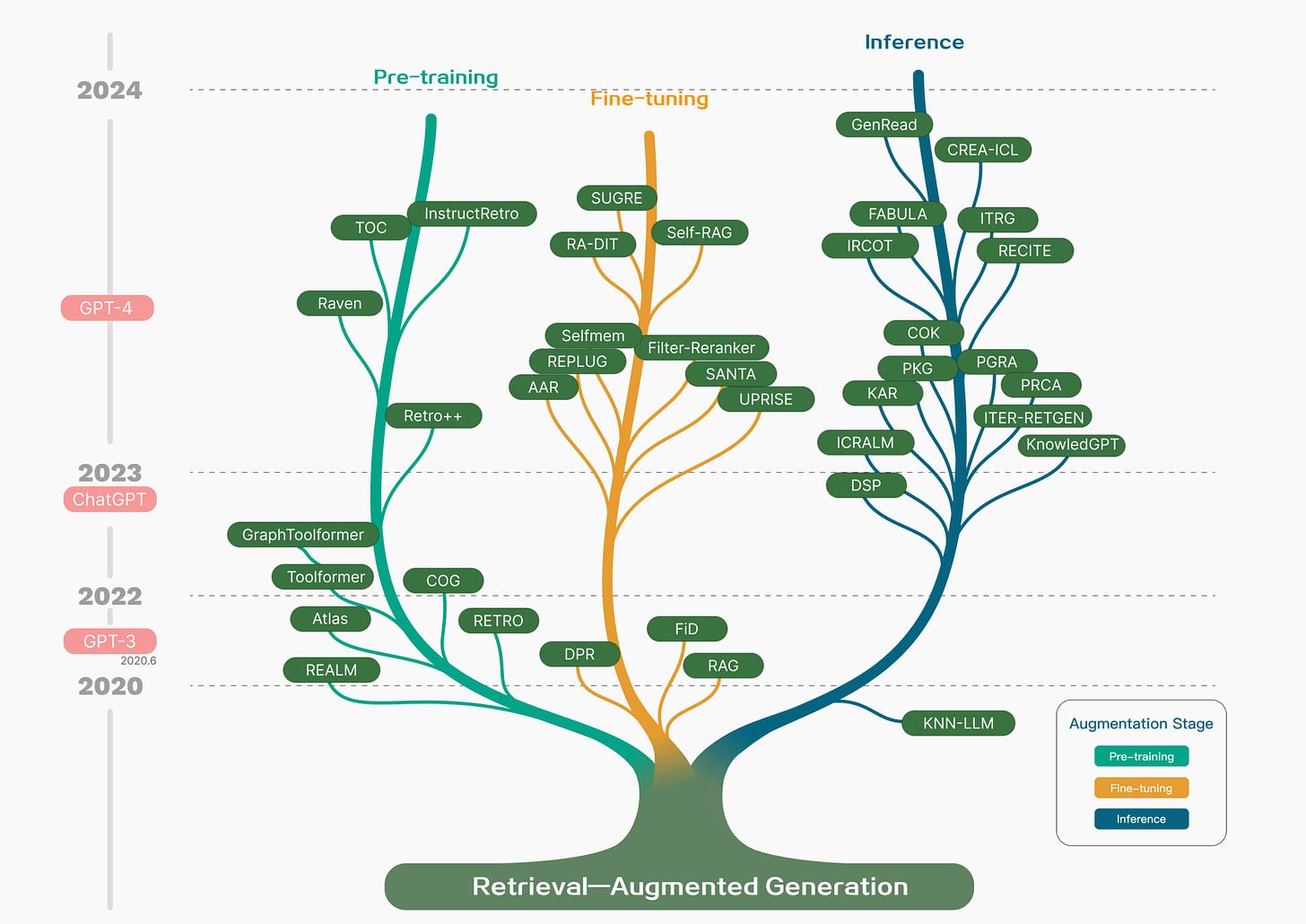
Technology tree of RAG research development featuring representative works By Gao et al 2023
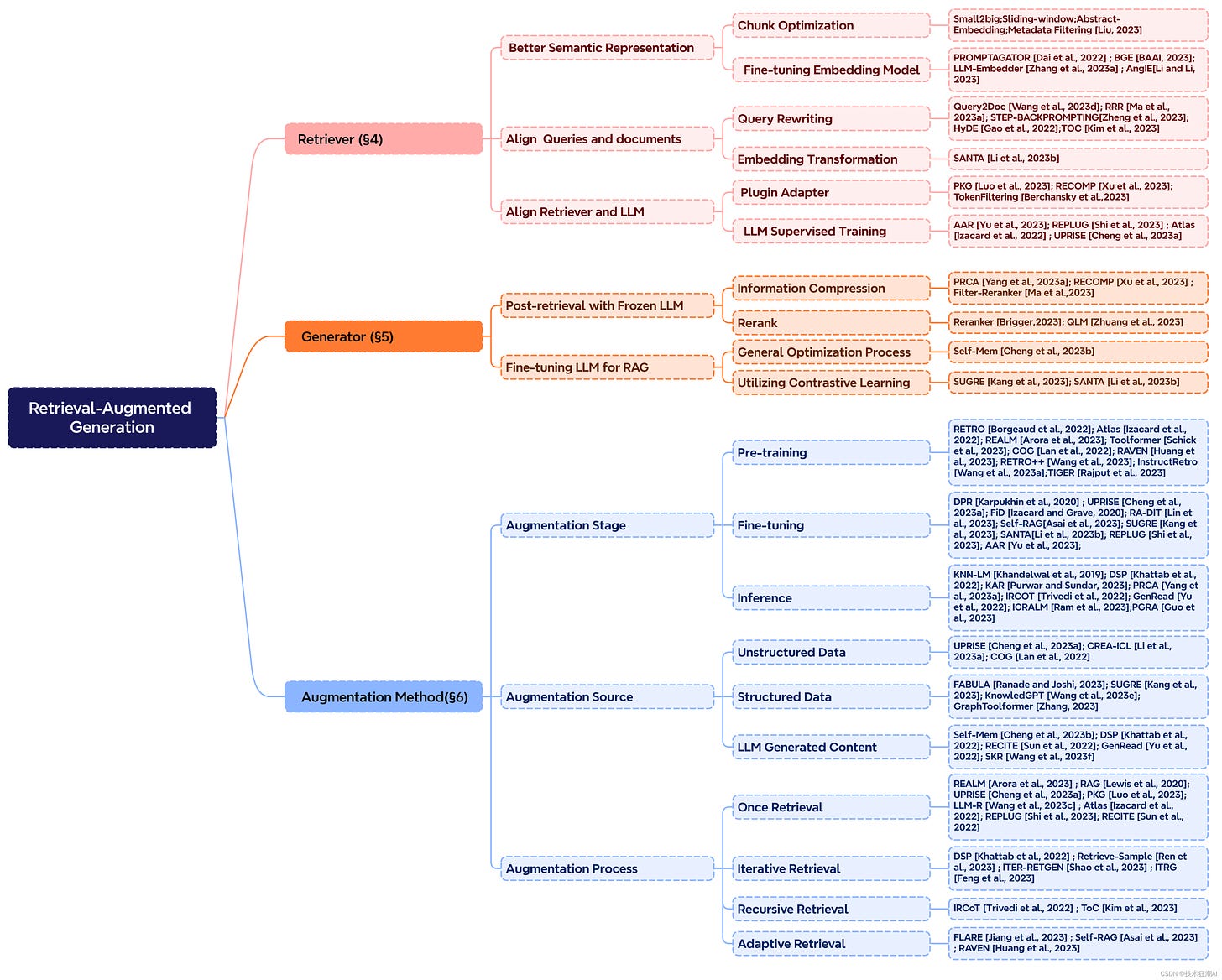
Taxonomy of RAG's Core Components
Retrieval
Sparse vs Dense Retrieval
- Sparse vectors are called sparse because they are sparsely populated with information (a lot of values are zero because most words don’t appear frequently).
- They require less computational resources to process and are often used to find information about a specific Brand or Object (ex. “Apple Inc.” not “Pear”) but can’t handle semantic meaning. Popular embedding examples are BM25 (Best Match 25) and TF-IDF (term frequency-inverse document frequency). This technique was used in one of the first instances of a RAG-like (LSTM as generator/reader) system for Q&A in 2017 By DrQA Chen et al.
- Dense retrieval enabled searching for semantic similarity. Unlike sparse vectors, the numbers in a dense vector represent learned relationships between words, capturing their meaning in a compact way.
- This means semantically similar words (like "doctor" and "physician") will have similar embeddings.
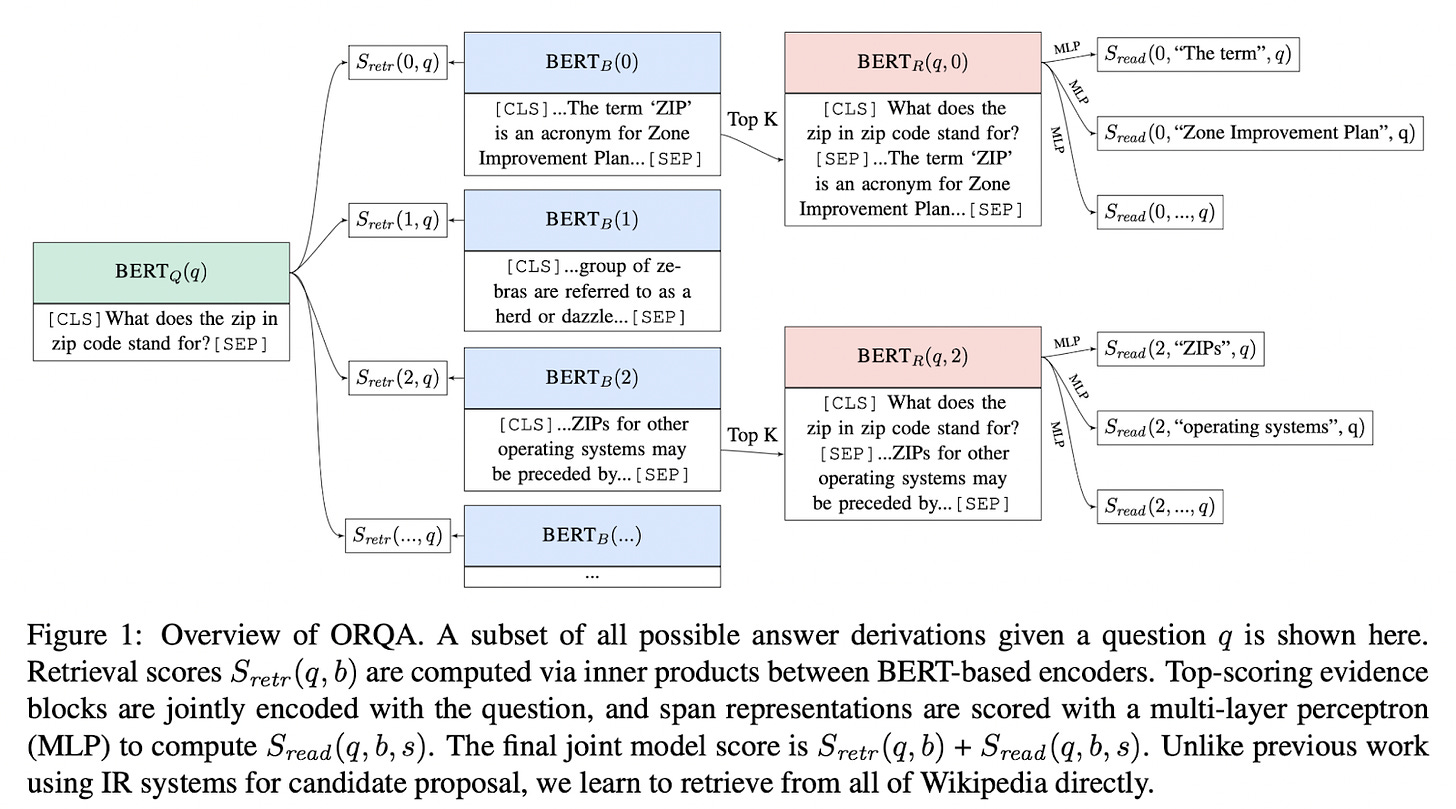
ORQA: Latent Retrieval for Weakly Supervised Open Domain Question Answering
- By Lee et al 2019
- One of the first Q&A systems built on dense embeddings is ORQA. It is trained end-to-end to jointly learn evidence retrieval and answering, using only question-answer pairs.
- It treats retrieval as an unsupervised, latent variable initialized via pre-training on an Inverse Cloze Task (predicting a sentence's surrounding context).
Vector DBs and Sparse & Dense Hybrids
- Maximum Inner-Product Search (MIPS) involves finding the vector in a given set that maximizes the inner product with a query vector.
- In simpler terms, given a set of vectors and a query vector, MIPS aims to identify the vector in the set most similar to the query vector based on the vector's inner product.
Faiss: A library for efficient similarity search
- By Johnson et al 2019
- A powerful library for similarity search and clustering of dense vectors that implements approximate nearest neighbor search (ANN) to solve MIPS search problems is FAISS which laid the foundation for many of today’s popular vector DBs.
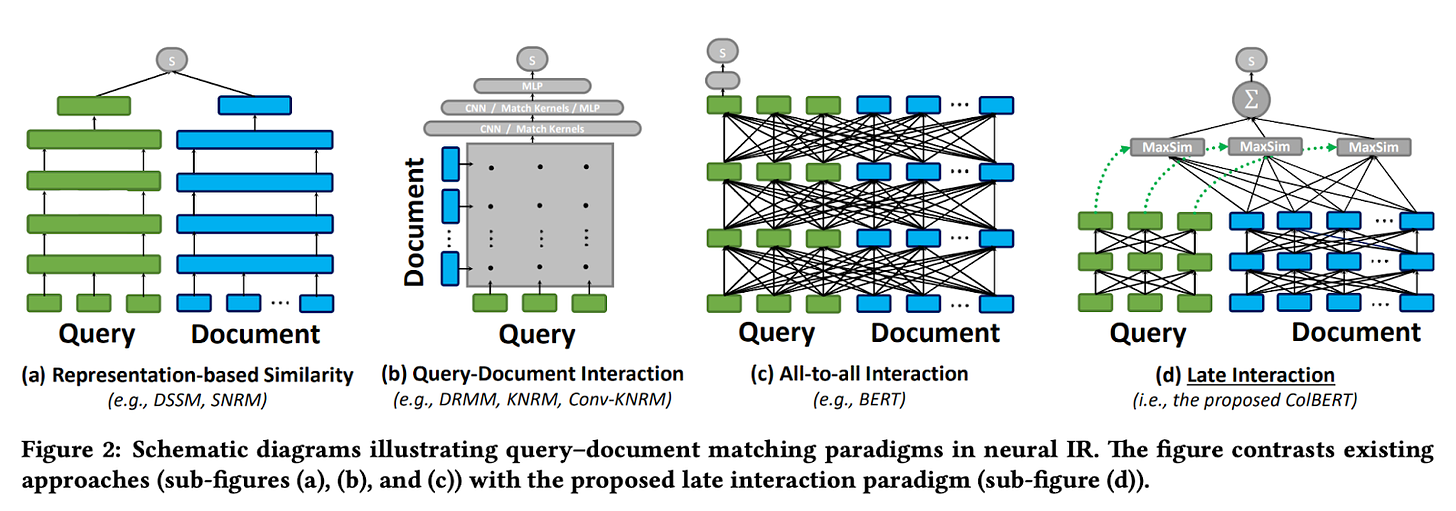
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- By Khattab et al 2020
- ColBert is a state-of-the-art neural search model. It enables efficient semantic search by independently encoding queries and documents before comparing their fine-grained similarity via late interaction (delaying interaction until after separate encodings are created).
- It finds maximum similarity (MaxSim) matches between each query token and document tokens, aggregating these to efficiently estimate overall relevance (up to 170x faster compared with prior BERT-based retrieval models).
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
- By Formal et al 2021
- An interesting hybrid between Sparse and Dense Retrievers is SPLADE. It is a sparse retriever that uses query expansion, identifying synonyms, and related terms for the query, enhancing its ability to capture semantic meaning even when not contained in the query.

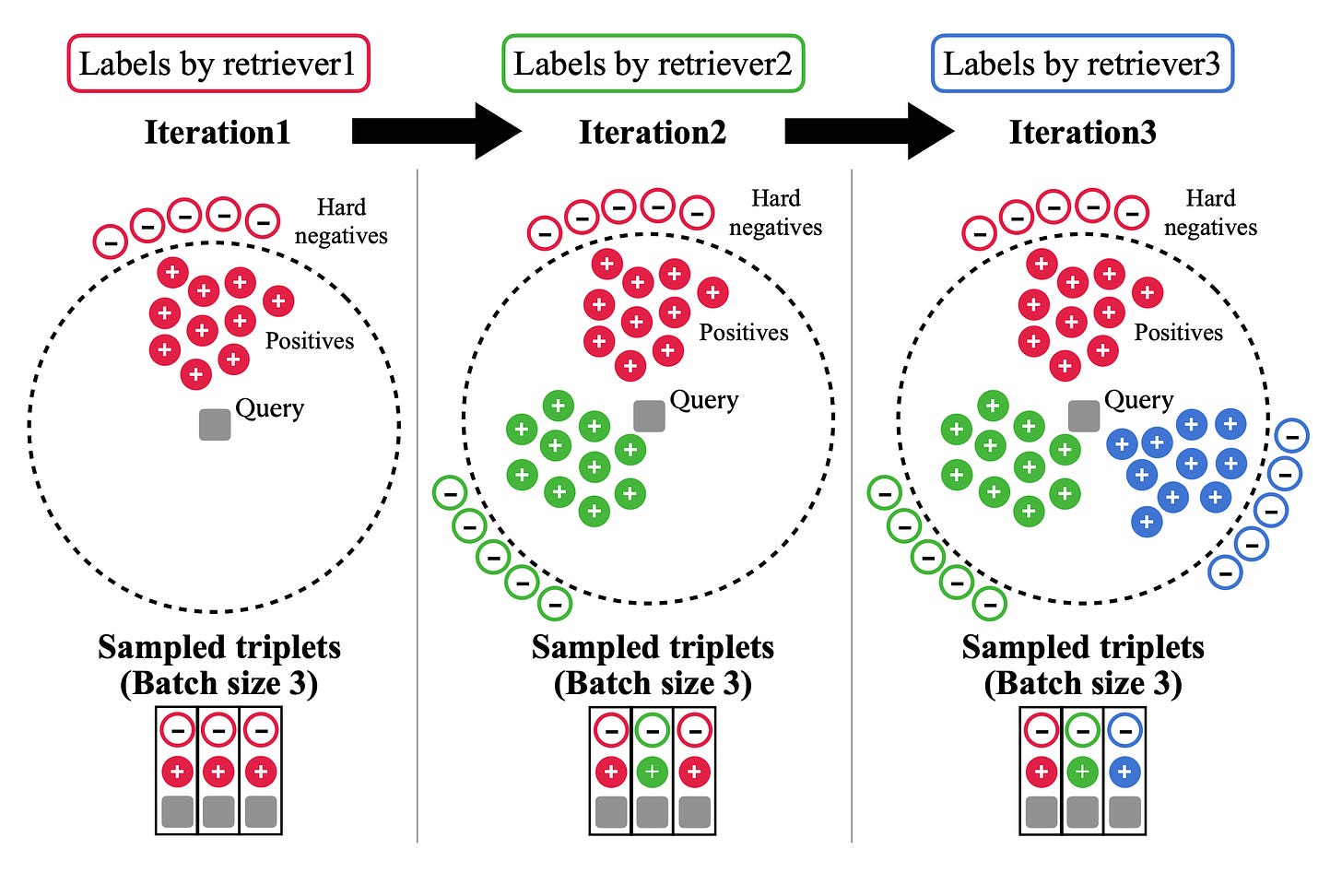
DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval
- By Lin et al 2023
- DRAGON, a generalized dense retriever, undergoes training with progressive data augmentation. This method gradually introduces more challenging supervisions and diverse relevance labels over multiple training iterations, enabling the model to learn complex relevance patterns effectively.
- By exposing the model to varied supervisions and sampling difficult negatives, DRAGON can generate high-quality representations, improving retrieval effectiveness across queries and documents. This strategy enhances DRAGON's language representation, leading to superior performance on unseen queries and documents.
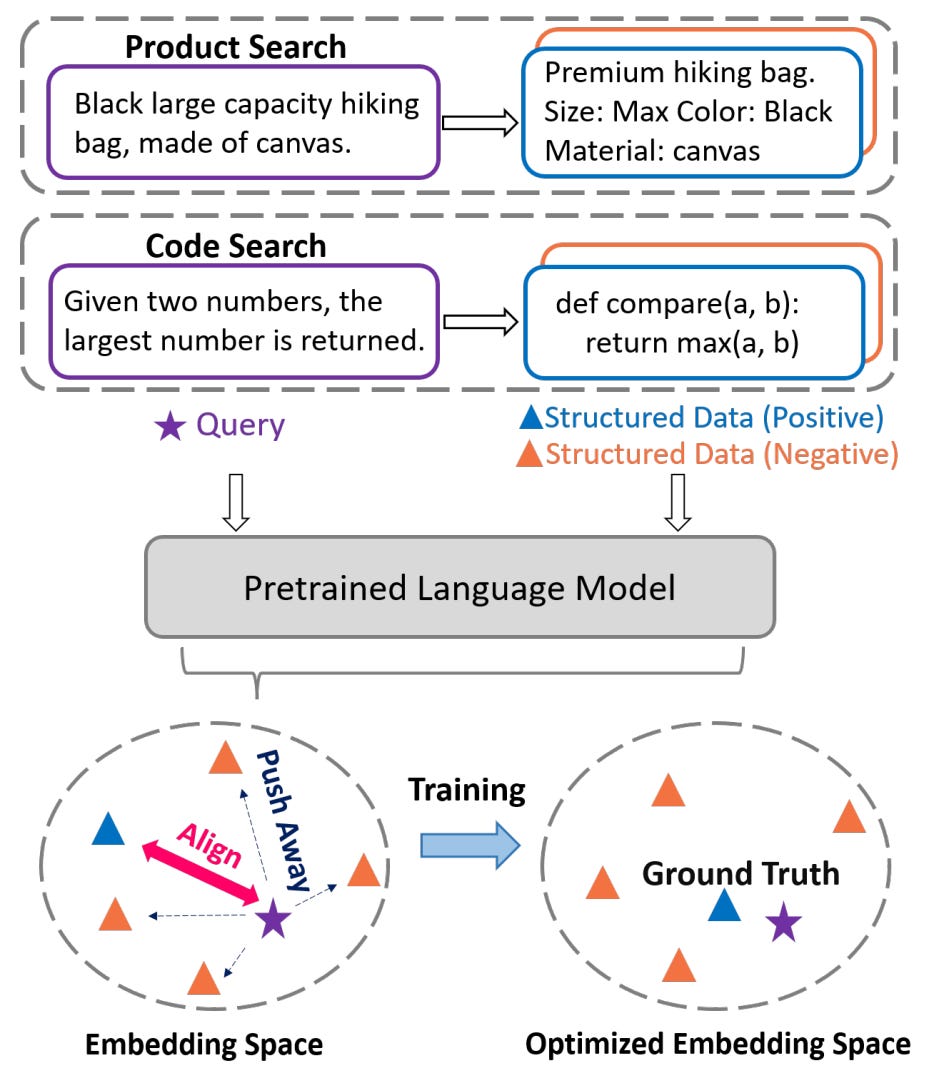
SANTA: Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data
- By Li et al 2023
- Structure Aware DeNse ReTrievAl (SANTA) addresses the challenge of aligning queries with structured external documents, especially when addressing the incongruity between structured data (such as code or product specifications) and unstructured data (such as text descriptions). It enhances the retriever's sensitivity to structured information through two pre-training strategies by:
- leveraging the intrinsic alignment between structured and unstructured data to inform contrastive learning in a structured-aware pre-training scheme; and
- implementing Masked Entity Prediction (utilizing entity-centric masking strategy that encourages LMs to predict and fill in the masked entities, fostering a deeper understanding of structured data).
🧊 Frozen vs Dynamic RAG 🔥
The industry has mostly viewed the components of the RAG architecture as separate components that work in isolation.
We can call this “Frozen RAG”. In contrast, some research has focused on iteratively improving the individual components (we can call this “Advanced RAG”).
Ideally, in a “Fully Dynamic” model, the gradients from the loss function would flow back into the entire system (end-to-end training): retriever, generator, and document encoder.
However, this is computationally challenging and has not been done successfully.
🔥 Dynamic Retriever but Fixed Generator 🧊
In-Context Retrieval-Augmented Language Models
- By Ram et al 2023
- The authors of this paper introduce a re-ranker, which ranks the retrieved results (using a simple, sparse BM25) before passing them into the LLMs context. This component is dynamic, i.e. the training signal of the entire model is backpropagated into the re-ranker.
- They show that this optimization can result in performance gains allowing a 345M parameter GPT-2 model to exceed the performance of a 1.5B GPT-2 model.
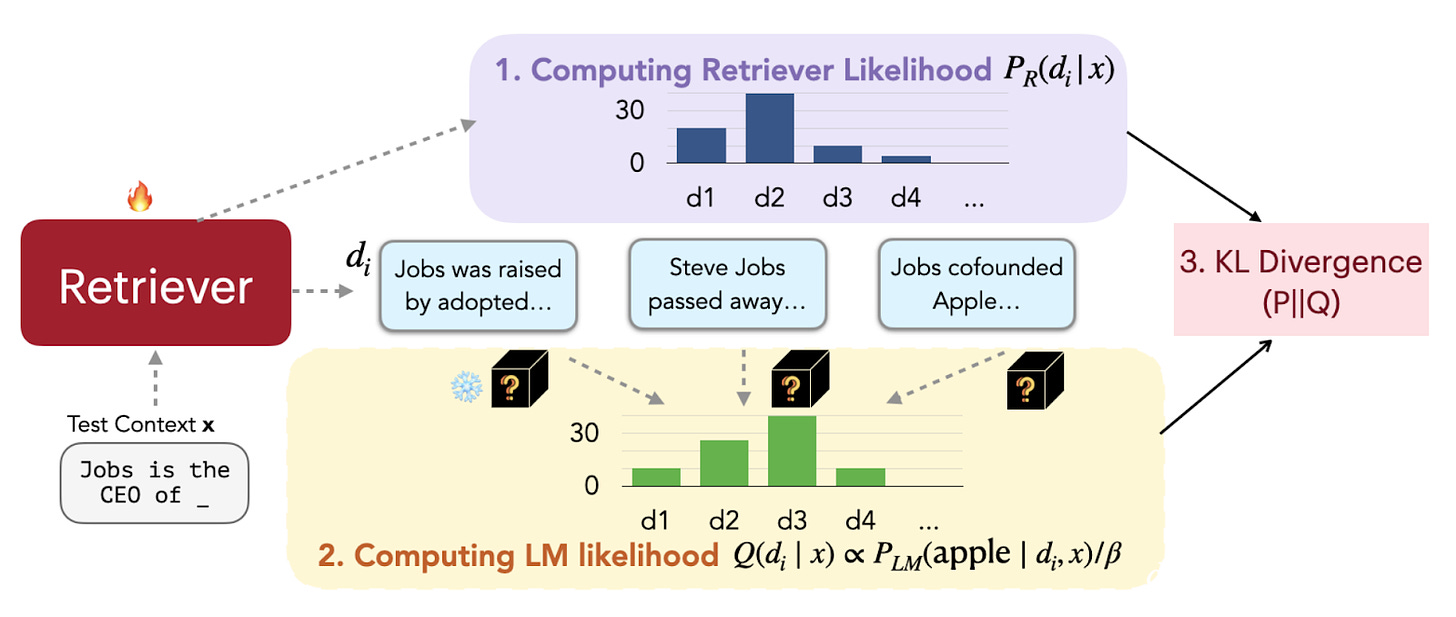
REPLUG: Retrieval-Augmented Black-Box Language Models
- By Shi et al 2023
- In this framework, the language model is treated as a frozen, black box but is augmented with a tunable retriever model. The name stems from the idea that you can plug any LM into the system.
- The retrieved documents/elements are presented to the LM separately, and we compute the perplexity of the model, given the query and the retrieved item (LM likelihood). This information is used to train the retriever to select:
- the highest Retriever Likelihood (using a similarity score) and
- the lowest perplexity documents. This framework does not work for any model that doesn’t provide a perplexity score.
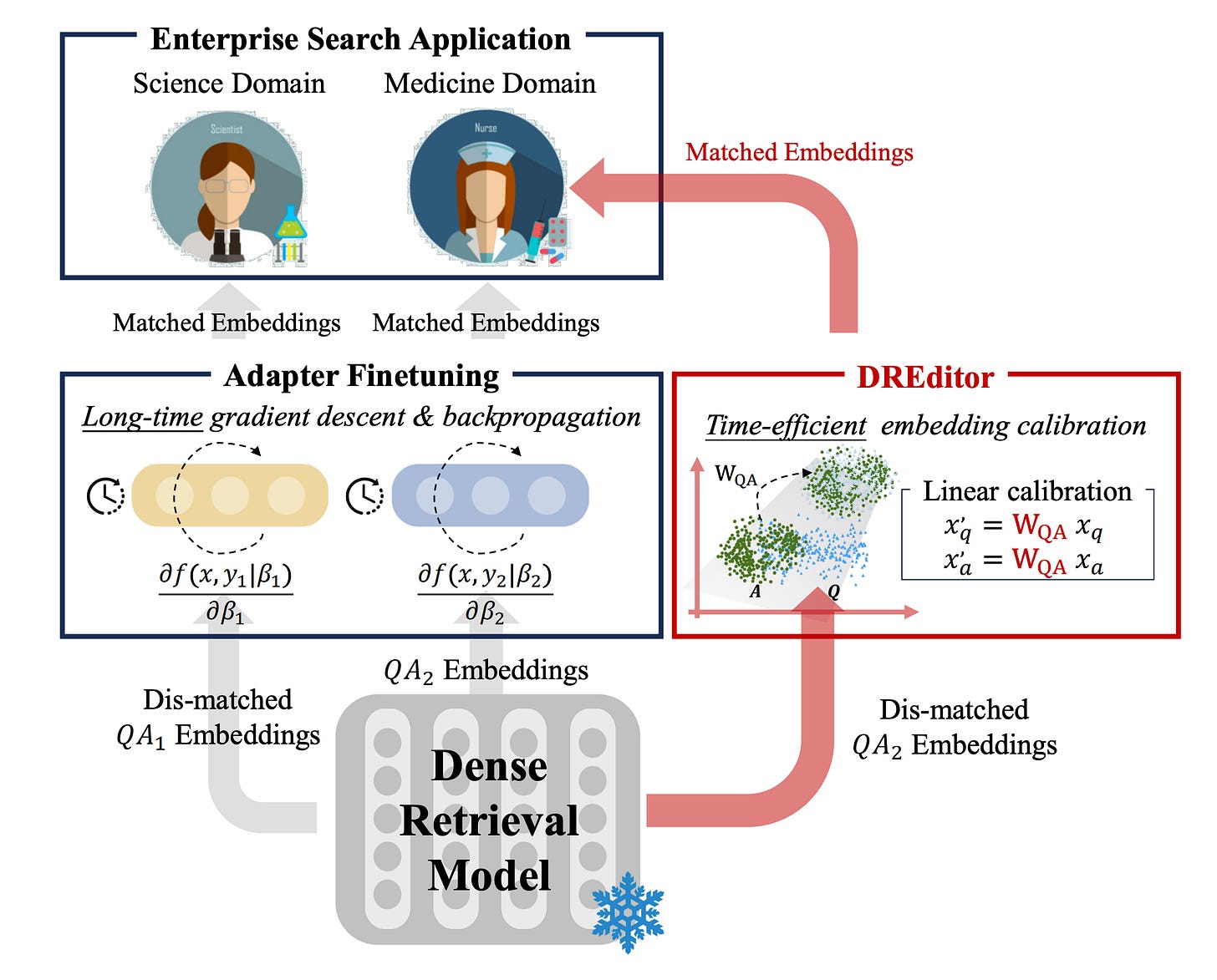
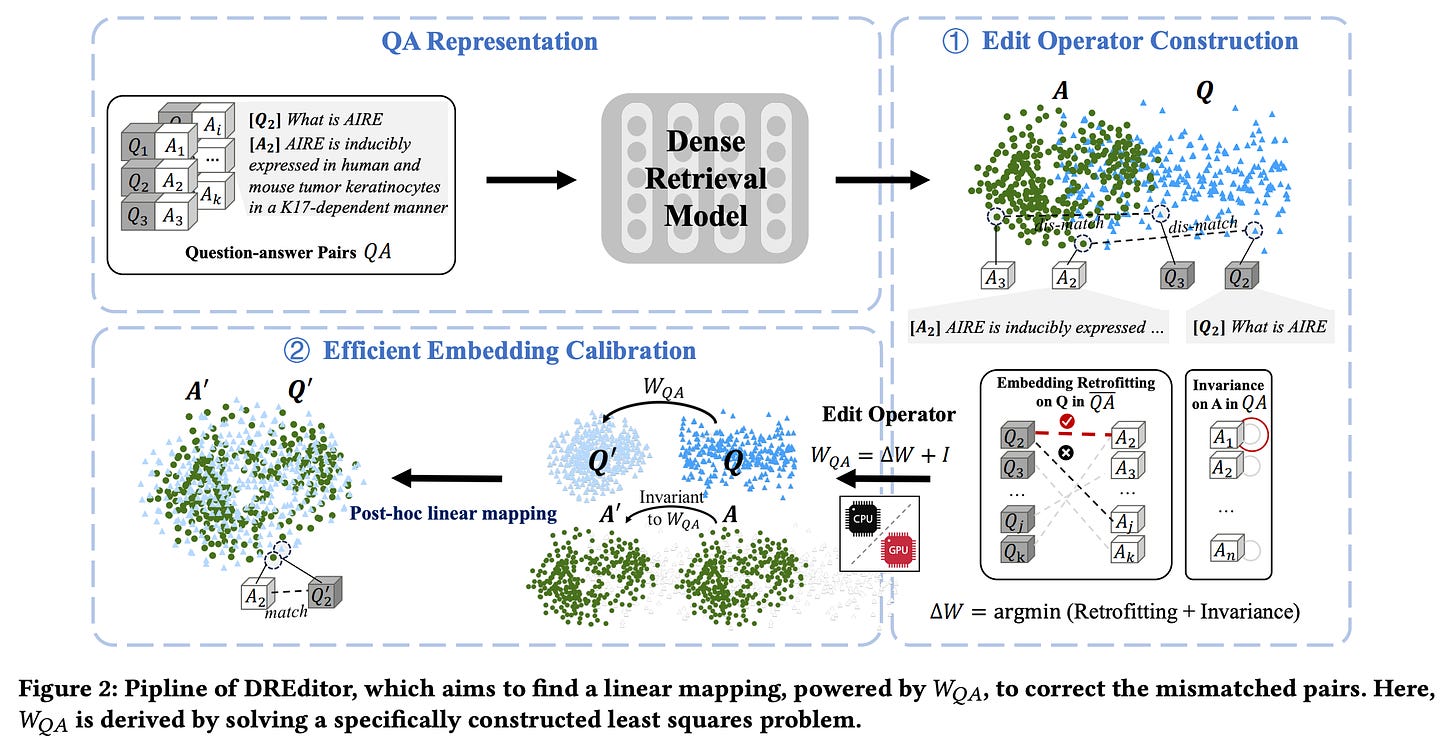
DREditor: A Time-efficient Approach for Building a Domain-specific Dense Retrieval Model
- By Huang et al 2024
- The authors propose DREditor, a time-efficient approach to customizing off-the-shelf dense retrieval models to new domains by directly editing their semantic matching rules (i.e. how the model compares vectors in the embedding).
- Motivated by needs in enterprise search for scalable and fast search engine specialization across corpora, DREditor calibrates model output embeddings using an efficient closed-form linear mapping (calculating the adjustment) instead of the usual long adaptation fine-tuning (similar to what REPLUG is doing).
- Experiments on domain transfer and zero-shot setups show 100-300x faster run times than fine-tuning while maintaining or improving accuracy.
🧊 Fixed Retriever but Dynamic Generator 🔥
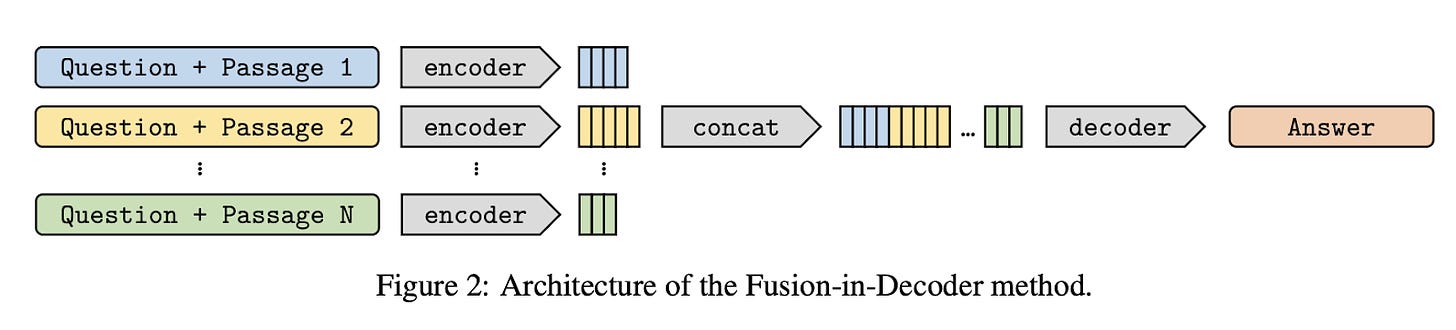
FiD: Fusion-in-Decoder
- By lzacard & Trave 2020
- This paper addresses a core limitation of many RAG systems, which is that we have to cram all the documents into the LM context, which is limited to the model’s context size.
- In this framework, we combine (concatenate) the query vector and the retrieved passages vectors before decoding them together into an answer.
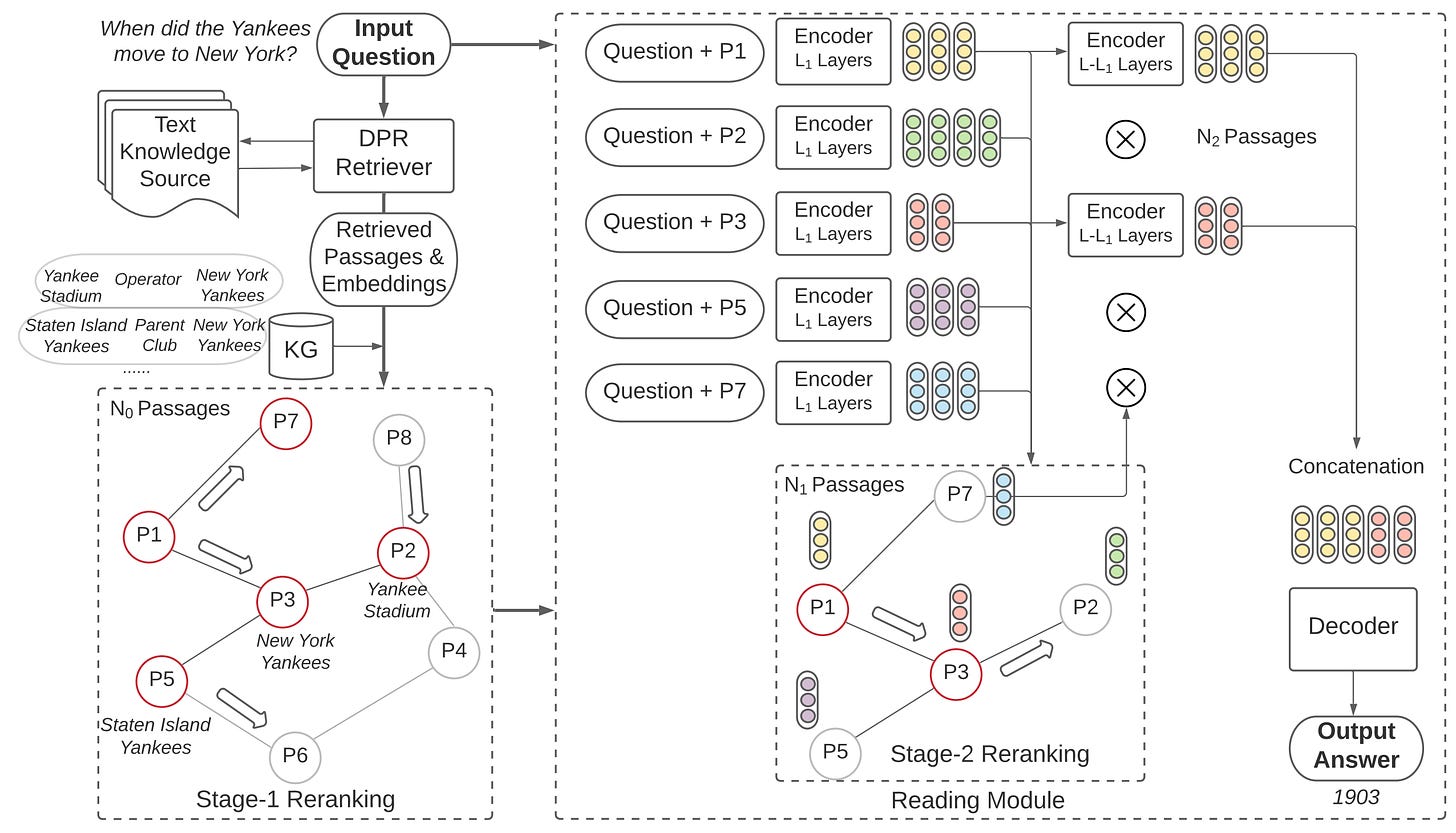
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
- By Yu et al 2021
- This paper adds another Graph Neural Net (GNN) re-ranking/filtering step to the FiD pipeline explained above.
- The authors correctly point out that FiD and other RAG frameworks are wrongly assuming that the content of the retrieved passages are independent from each other. However, the entities referenced in the retrieved passages are likely related to each other and their relationship can be modeled.
- The steps of the framework can be summarized as:
- Retrieve relevant passages & embeddings via Dense Passage Retrieval (DPR).
- Construct knowledge graph from WikiData and neighboring context passages.
- Utilize Graph Neural Network (GNN) for iterative re-ranking of passages based on semantic relationships.
- Update passage embeddings to eliminate less relevant passages and enhance top-ranked selections for answer generation.
(For more details, you can find the main author’s presentation of the paper here).
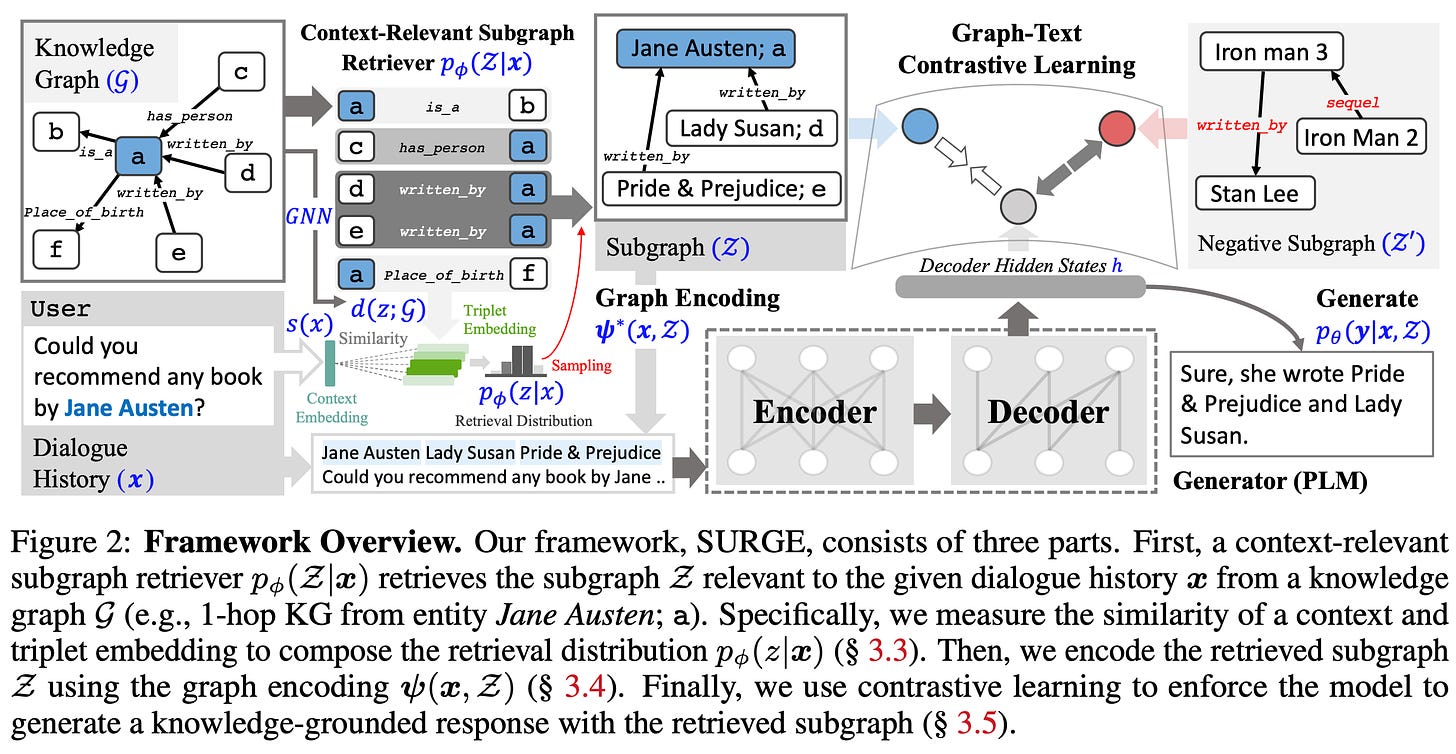
SURGE:Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation
- By Kang et al 2023
- SUbgraph Retrieval-augmented GEneration (SURGE) addresses the problem with prior graph-based retrieval techniques where the LM can get confused by irrelevant content. Their framework aims to retrieve only a context-relevant subgraph and is end-to-end trainable along with a generative model.
- The GNN-based context-relevant subgraph retriever extracts relevant pieces of knowledge from a Knowledge Graph (no vector DB), and extracts candidate triplets (3 nodes). For each triplet, we generate a Retrieval Distribution by calculating the inner product between the Context Embedding (based on the Dialog History) and our candidate triplet. This process involves exponentiating the inner product of the triplet embedding and the context embedding, resulting in a score that determines the relevance of the triplet to the dialogue history.
- The authors further leverage contrastive learning to train the model to distinguish between knowledge-grounded responses (using the retrieved subgraph) and irrelevant alternatives, mitigating exposure bias that arises from only showing input and a single "correct" output during training.
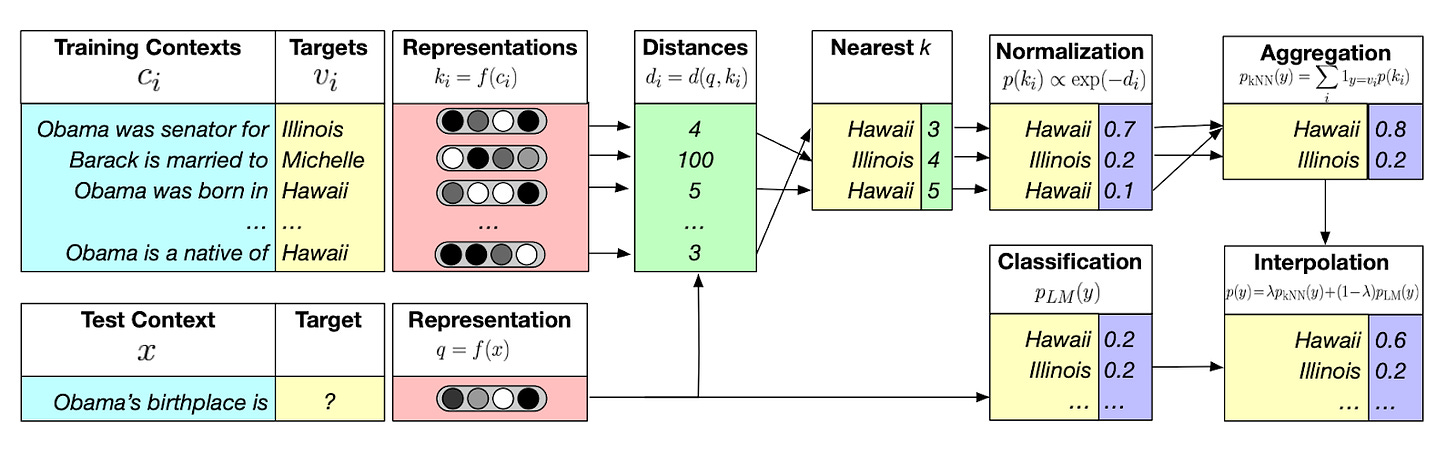
KNN-LM: Generalization through Memorization: Nearest Neighbor Language Models
- By Khandelwal et al 2019
- This is another interesting paper in which the authors attempt to make the LM outputs more grounded. This is done by comparing the vector distance of the model’s initial prediction to similar/neighboring passages from a data store.
- The database in this case is a collection of key-value pairs comprised of a token and its proceeding tokens (context). In the end, the normalized KNN model outputs, ranked by their distances, and the LM output distribution are merged (interpolated) to converge on the final output.
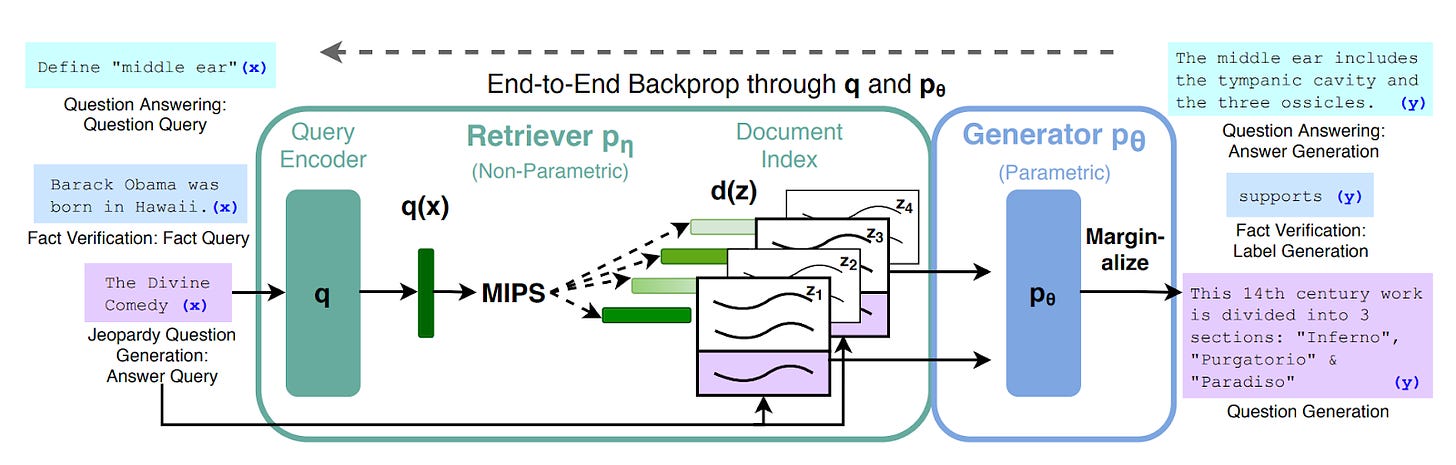
RAG: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- By Lewis et al 2020
- This paper, mentioned in the introduction of this blog post, is the origin of the idea of a dynamic, end-to-end trained RAG system backpropagating into both, the retriever and the generator. However, the document encoder step in this and the next paper is still static.
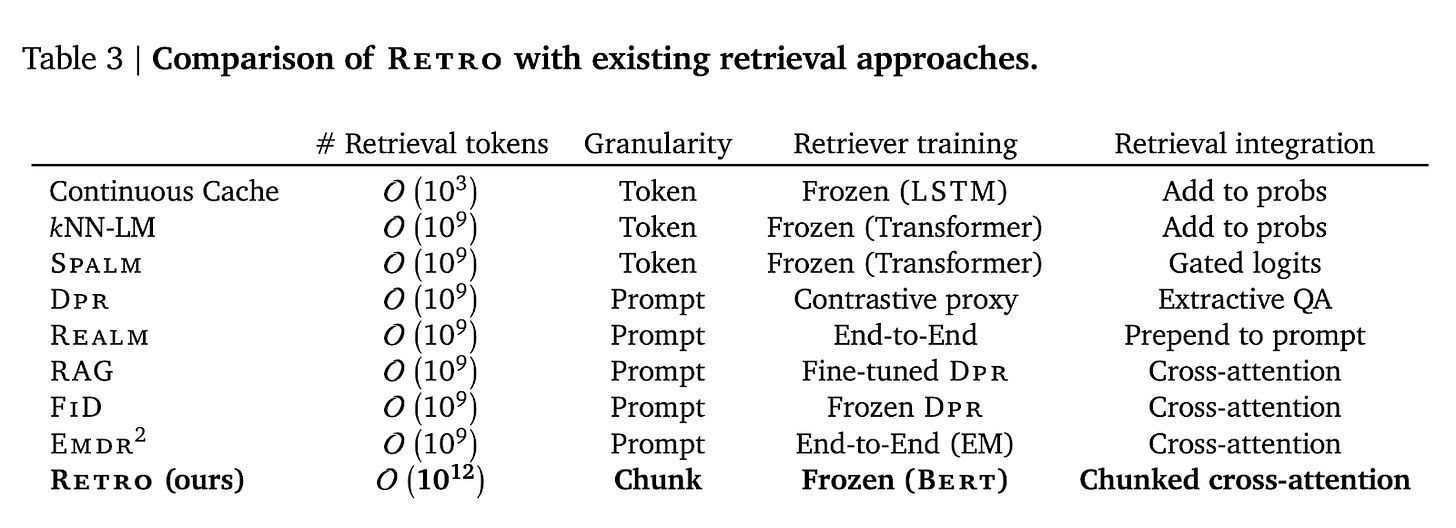
RETRO: Improving language models by retrieving from trillions of tokens
- By Borgead et al 2022
- This paper showed that RAG using an LM pre-trained from scratch can outperform a 25x bigger model in terms of perplexity. I won't go into too much detail about the exact architecture because it is unclear if this paper is reproducible. (DeepMind never published the paper’s code, and I heard that other tier-1 AI research companies failed to reproduce it).
- Essentially, in RETRO, the retrieved chunks are selected similarly to the Generalization through the Memorization/KNN process above, then added to the query, and processed by the transformer encoder (using chunked cross-attention). In contrast, in RAG and related architectures, the retrieved passages are used as additional context for the transformer decoder.
Fully Dynamic RAG
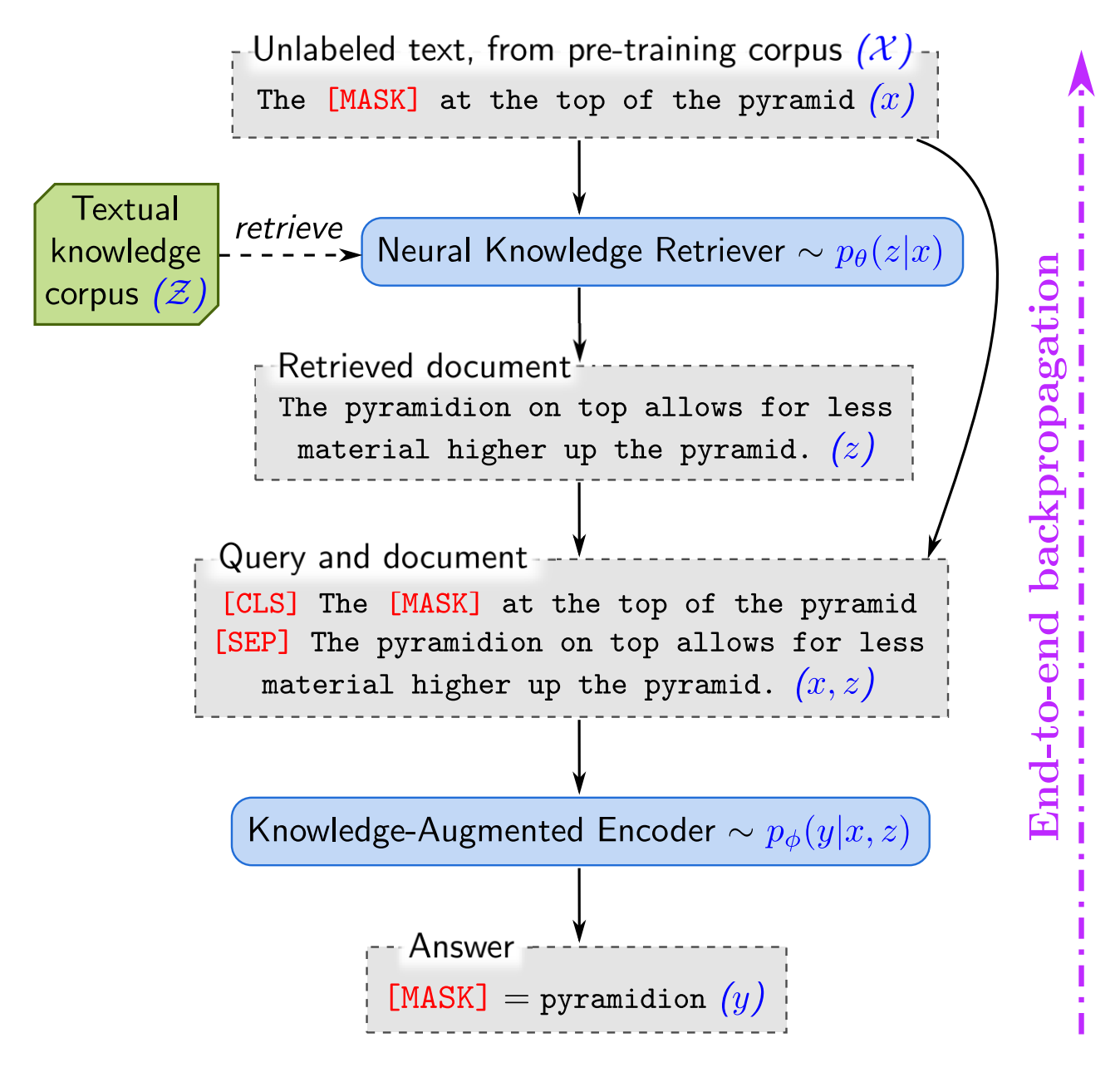
REALM: Retrieval-Augmented Language Model Pre-Training
- By Guu et al 2020
- This paper represents the first fully dynamic RAG model (in which both the retriever, the generator, and the document encoder are updated).
- Its main limitation or downside is that it is not truly generative, just BERT-based, limiting its ability to produce completely novel/free-form text. Updating the document encoder is costly.
- REALM introduces asynchronous updates, where the knowledge base is re-embedded in batches.
Other Retrieval Research
Query/retrieval system related
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- By Sarthi et al. 2024
- Sometimes reasoning about a text requires a more abstract or holistic understanding of it. This is where simple chunk-based retrieval fails.
- In the RAPTOR technique, similar text chunks are clustered and then summarized. The summaries, in turn, are then clustered and summarized. These leaves and summaries are organized into a tree structure.
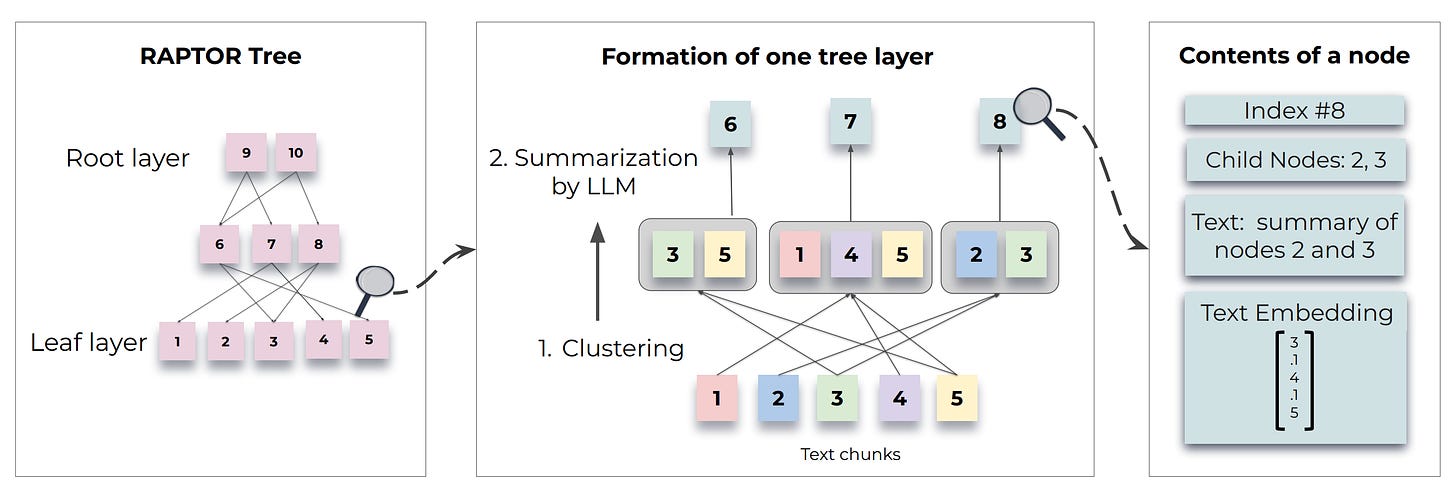
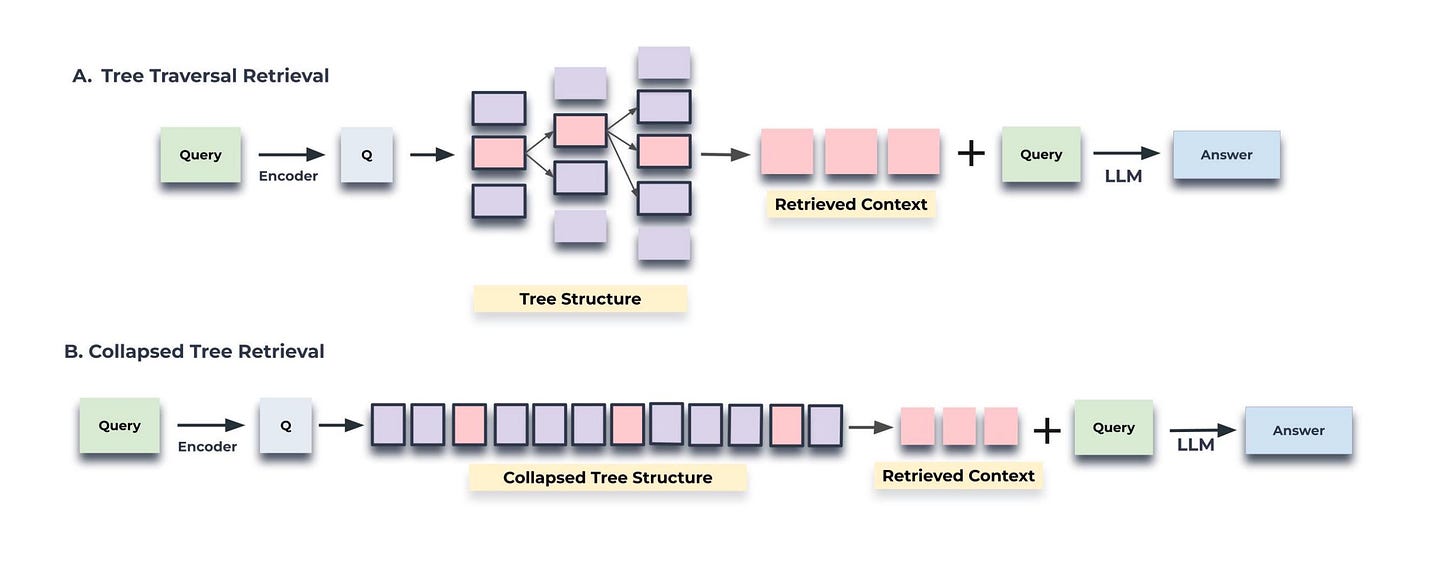
- RAPTOR supports two retrieval strategies:
- Tree Traversal, which retrieves nodes layer by layer, and
- Collapsed Tree, which flattens the tree for a breadth-first search. Collapsed Tree is more effective in most cases because it retrieves cluster summaries and leaf chunks.
- Benchmarks show RAPTOR's effectiveness in improving RAG's accuracy by up to 20%, especially for queries requiring comprehensive contextual understanding.
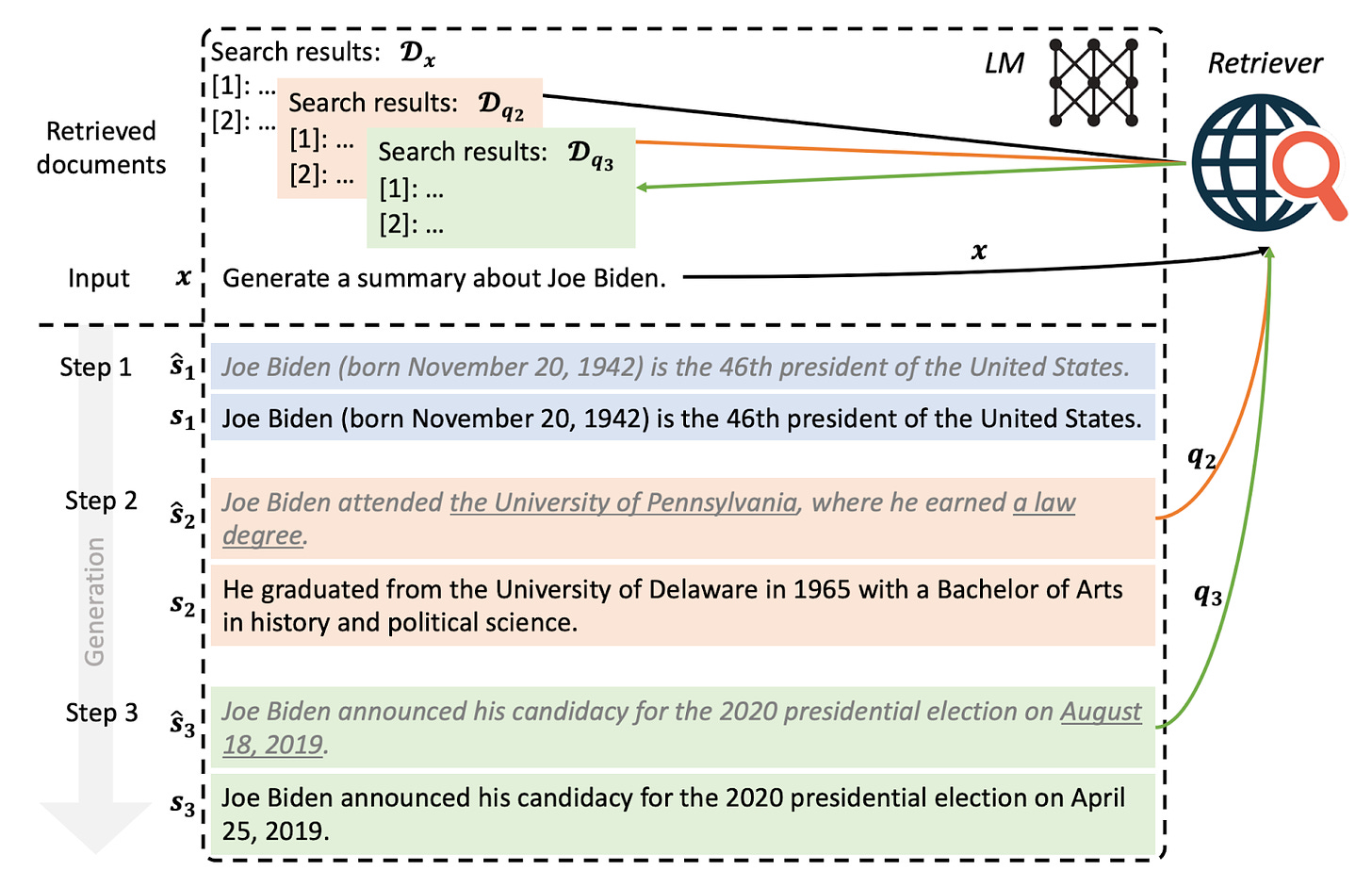
FLARE: Forward-looking active retrieval augmentation
- By Jiang, Xu, Gao, Sun et al 2023
- A limitation of some of the above-explained techniques is that they sequentially retrieve and then generate.
- This paper proposes a system that iteratively predicts the next sentence to retrieve relevant context if it contains low-confidence tokens.
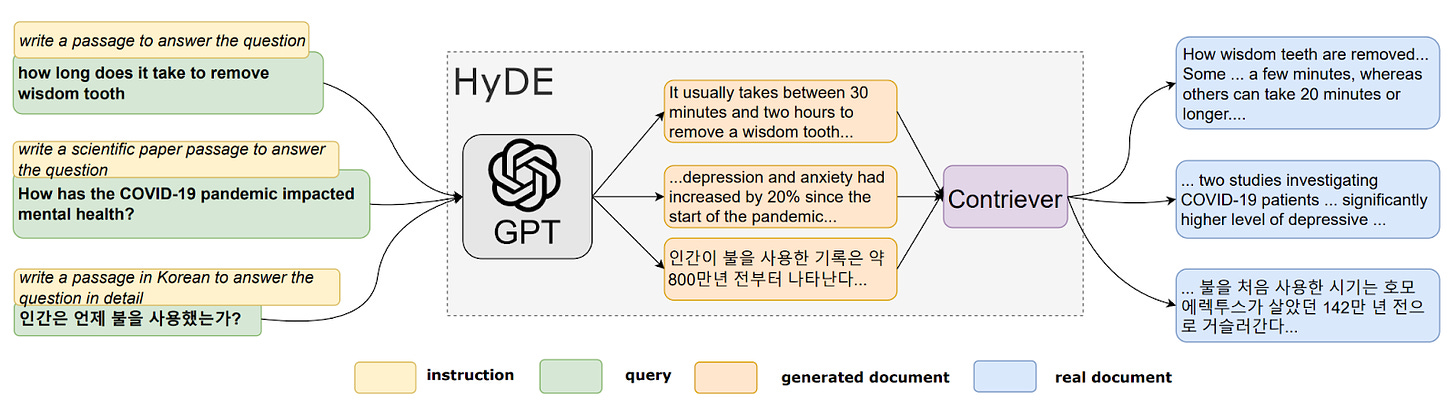
HyDE: Hypothetical Document Embeddings
- By Gao, Ma et al 2022
- A core problem of retrieval is that the user's query might not capture their actual intent. I.e. there is a difference between what someone thinks they want to know about vs. what they actually want to know about.
- The paper aims to address that through an intermediate query-rephrasing step. This leads to a process where the main weakness of vanilla LLMs is dampened by their main weakness: Hallucination against hallucination.
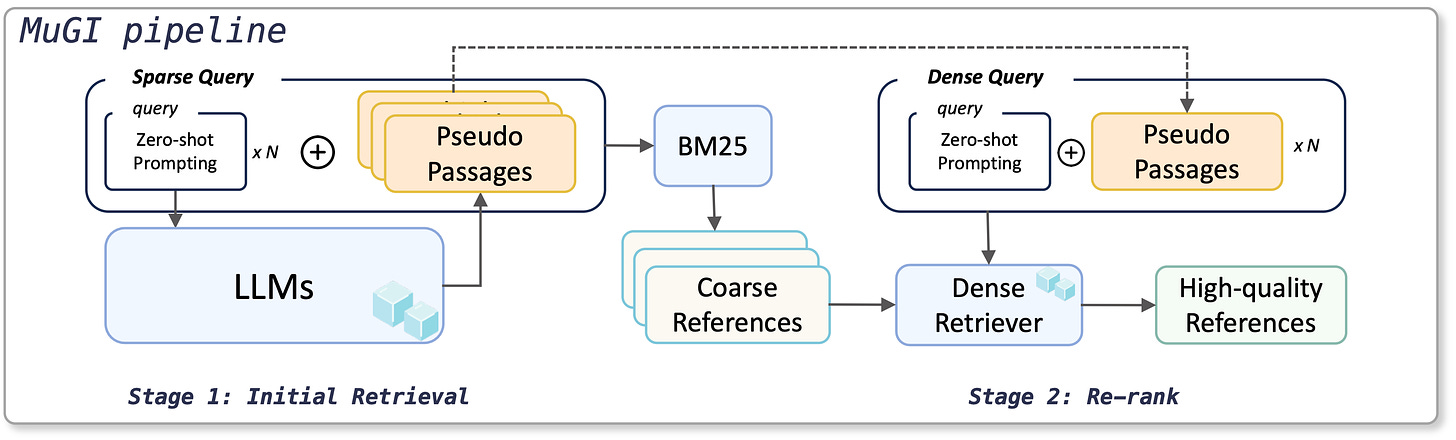
MuGI: Enhancing Information Retrieval through Multi-Text Generation Integration with Large Language Models
- By Zhang et al 2024
- This paper builds on the above Query Re-writing idea. It introduces a framework named Multi-Text Generation Integration (MuGI).
- The framework involves prompting an LLM to generate multiple pseudo-references, which are then dynamically integrated with the original query for retrieval. The model is used both for re-ranking and retrieval.
Query Rewriting for Retrieval-Augmented Large Language Models
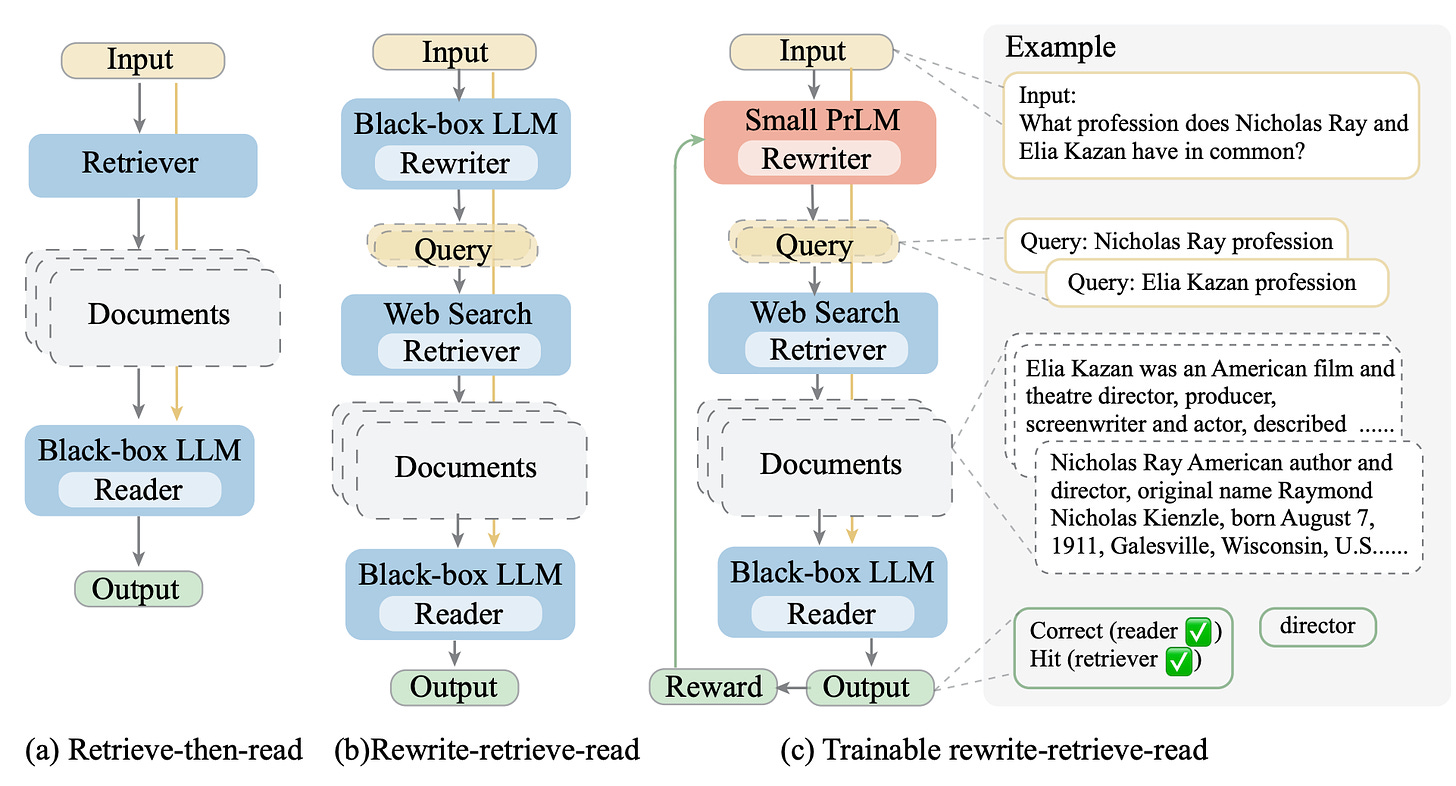
- By Ma et al 2023
- This paper introduces a trainable rewrite-retrieve-read framework (reversing the traditional retrieval and reading order, focusing on query rewriting) that utilizes the LLM performance as a reinforcement learning incentive for a rewriting module.
Context related
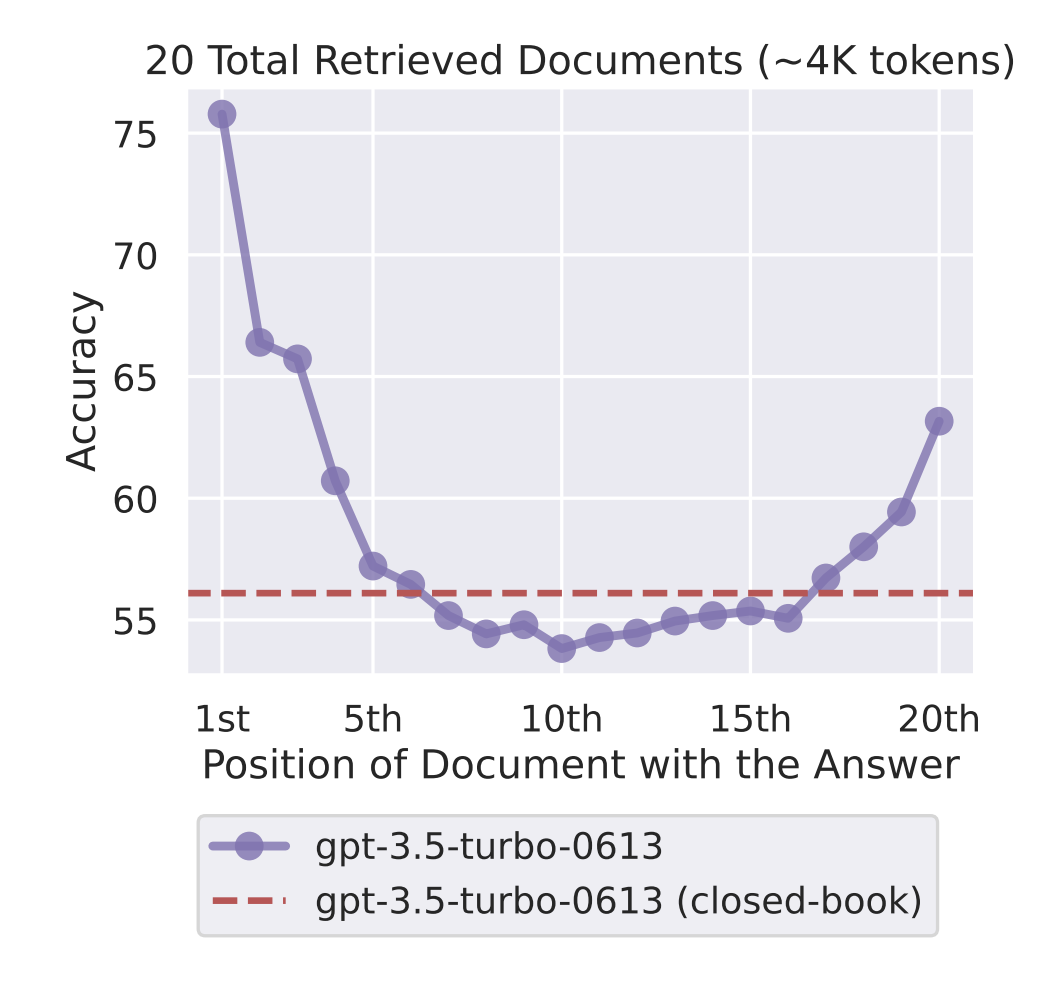
Lost in the Middle: How Language Models Use Long Contexts
- By Liu et al 2023
- This paper points out a core problem with passing a list of context items into the model, sorted by their relevance, as it will attend more to documents at the beginning and the end.
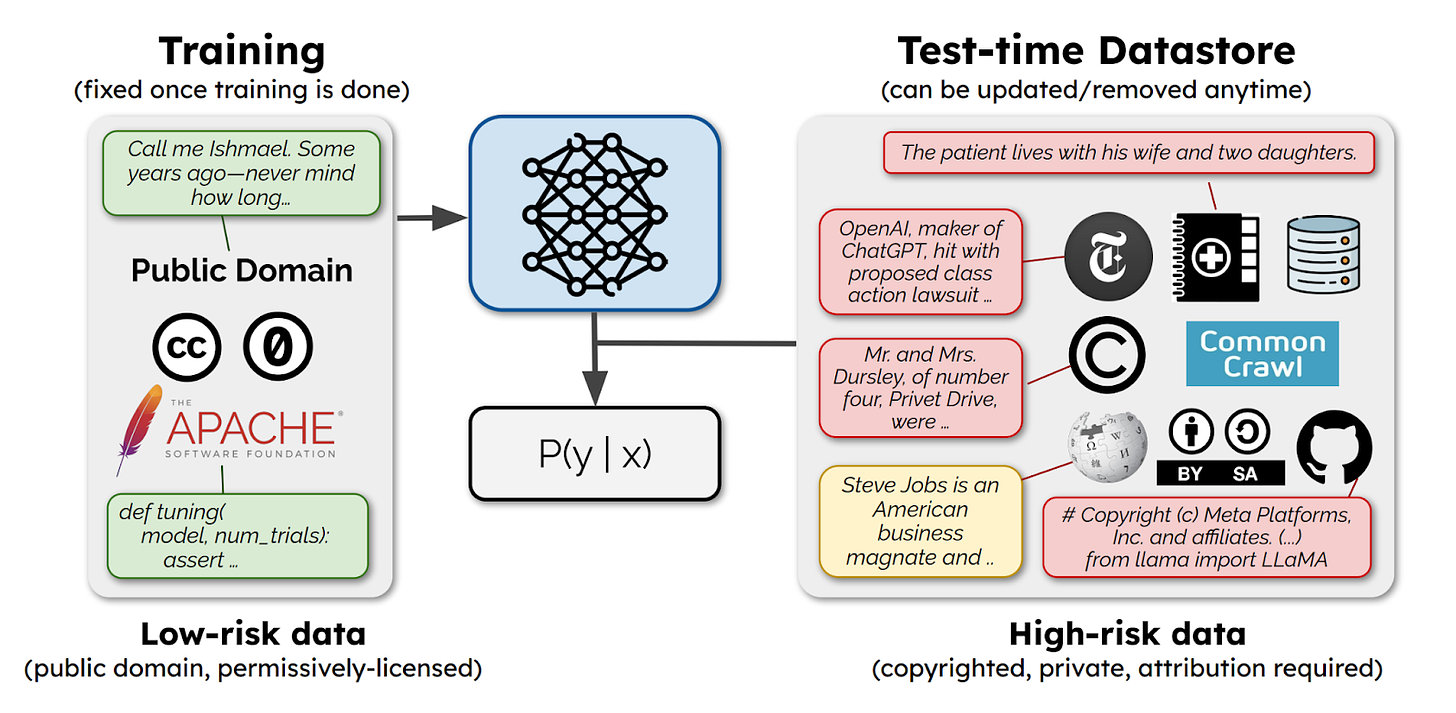
SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore
- By Min, Gururangan et al 2023
- This paper suggests a solution to recent copyright infringement lawsuits where companies like the New York Times are suing model training companies for training on their paywalled data.
- The authors suggest only using public domain data during training but augmenting the model with “higher-risk data” during test/inference time.
Augmentation/interactivity
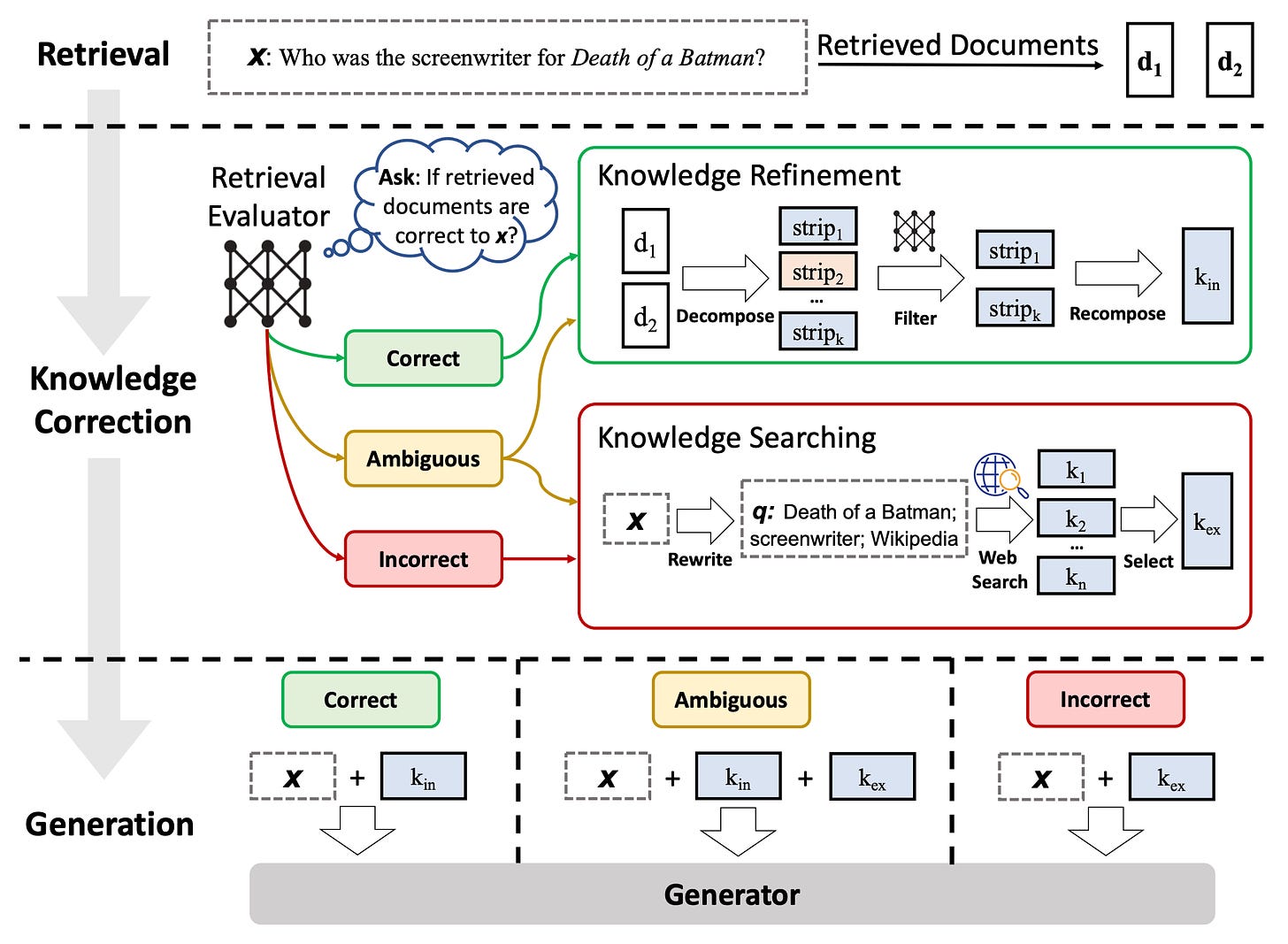
CRAG: Corrective Retrieval Augmented Generation
- By Yan et al 2024
- This paper proposes a method to improve the robustness of retrieval-augmented language models when retrieval fails to return relevant documents.
- CRAG tackles this by:
- Assessing retrieved document quality with a confidence score,
- Launching web searches for inaccurate retrievals, and
- Refining knowledge with a decompose-then-recompose algorithm (segmenting the document into fine-grained strips, scoring each for relevance, filtering out irrelevant strips, and concatenating the relevant ones). CRAG improves RAG performance on short- and long-form generation tasks across diverse datasets, showcasing its generalizability and robustness.
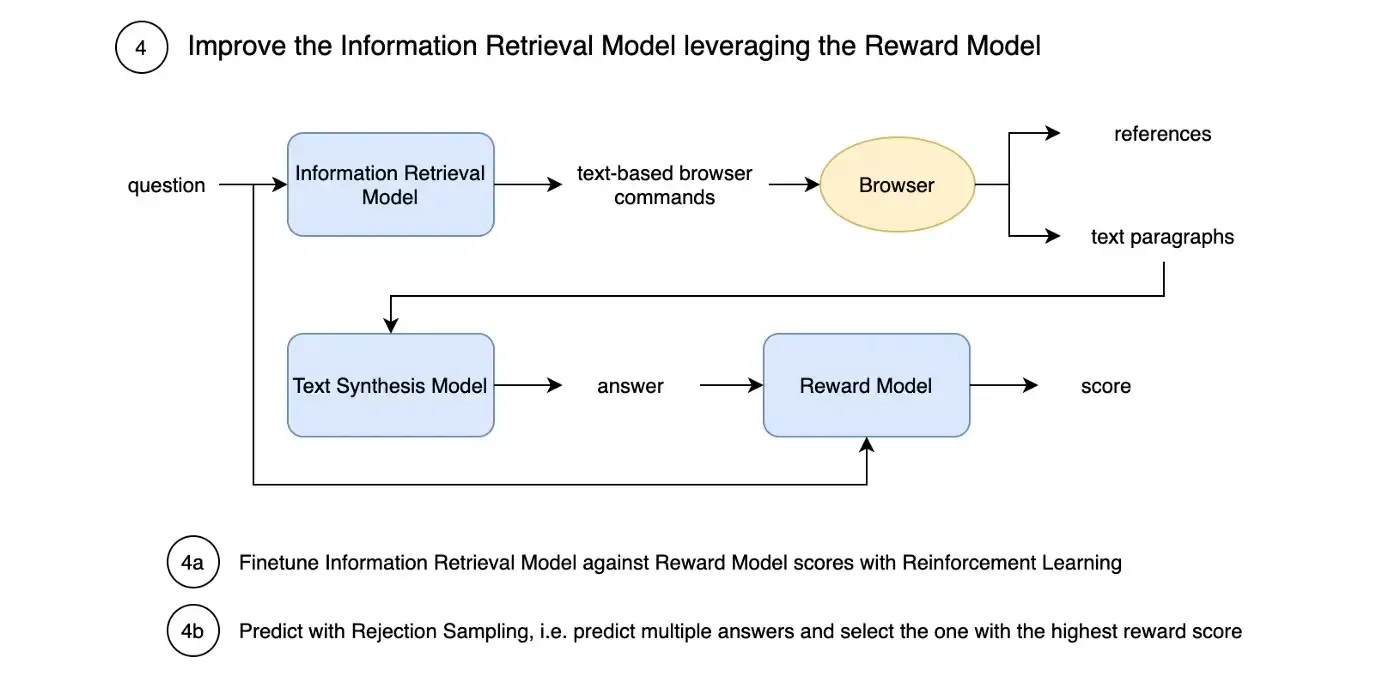
WebGPT: Browser-assisted question-answering with human feedback
- By Nakano et al 2021
- The system presented here could be termed Web Search Augmented Generation. The Information Retrieval Model receives the query and can output browser commands (like clicks, and scrolling) to extract relevant paragraphs from web pages it determines as informative.
- It's trained on human demonstrations with Imitation Learning (Behavior cloning).
- In the second step, a separate Text Synthesis Model synthesizes the answers.
- Finally, a reward model predicts the system output score. The entire system is then fine-tuned using human feedback, i.e. the reward model (RLHF).
Toolformer: Language Models Can Teach Themselves to Use Tools
- By Shick et al 2021
- This paper is the generalization of the idea of Augmented Generation. It presents a solution that allows LLMs to use external tools via simple APIs.
- Tool usage shown in the paper includes a calculator, a Q&A system, search engines, a translation system, and a calendar.
- The steps can be summarized as follows:
- The authors annotate a large text dataset and sample potential locations in the text where tool API calls could be useful,
- At each location, they generate possible API calls to different tools,
- They execute these API calls and insert the call+response back into the original text (like "[QA(Who founded Apple?) -> Steve Jobs]"),
- They check if adding the app call reduced the perplexity loss of the LM for predicting the following token and keep the API call if it did, and
- The resulting training data is used to fine-tune the original LM.
- This system has many limitations such as the inability to use tools in a chain, its ability to use tools interactively, or its ability to take into account the cost of the use of a tool.

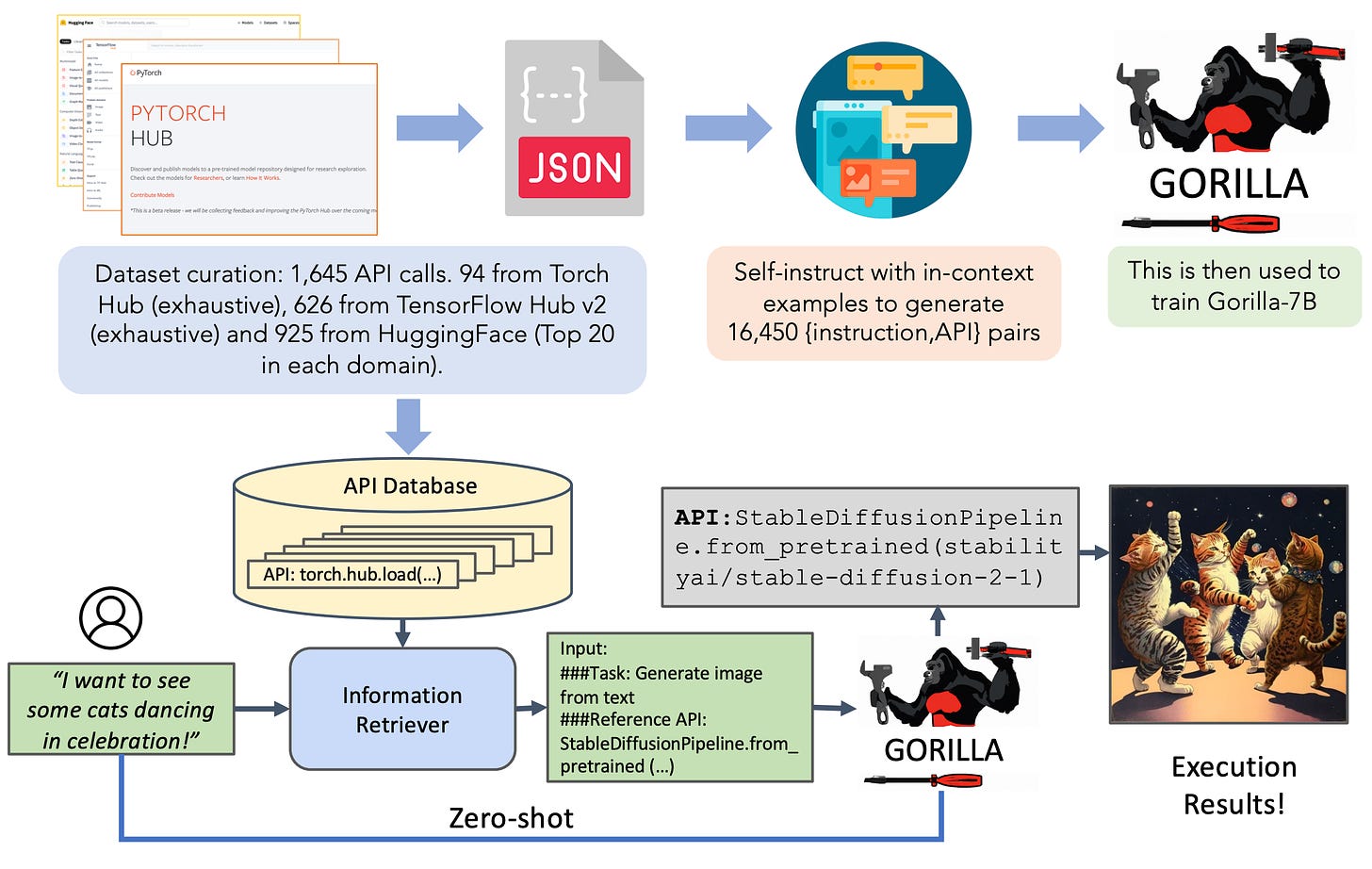
Gorilla: Large Language Model Connected with Massive APIs
- By Patil et al 2023
- One limitation of the previous paper is that tool use is limited to a small set of tools. In contrast, the authors of this paper develop a retrieval-based finetuning strategy to train an LLM, called Gorilla, to use over 1,600 different deep learning model APIs (e.g., from HuggingFace or TensorFlow Hub) for problem-solving. First, it downloads the API documentation of various tools. It then uses this data to create a question-answer pair dataset (using self-instruct). Finally, the 7B model is finetuned over this dataset in a retrieval-aware manner.
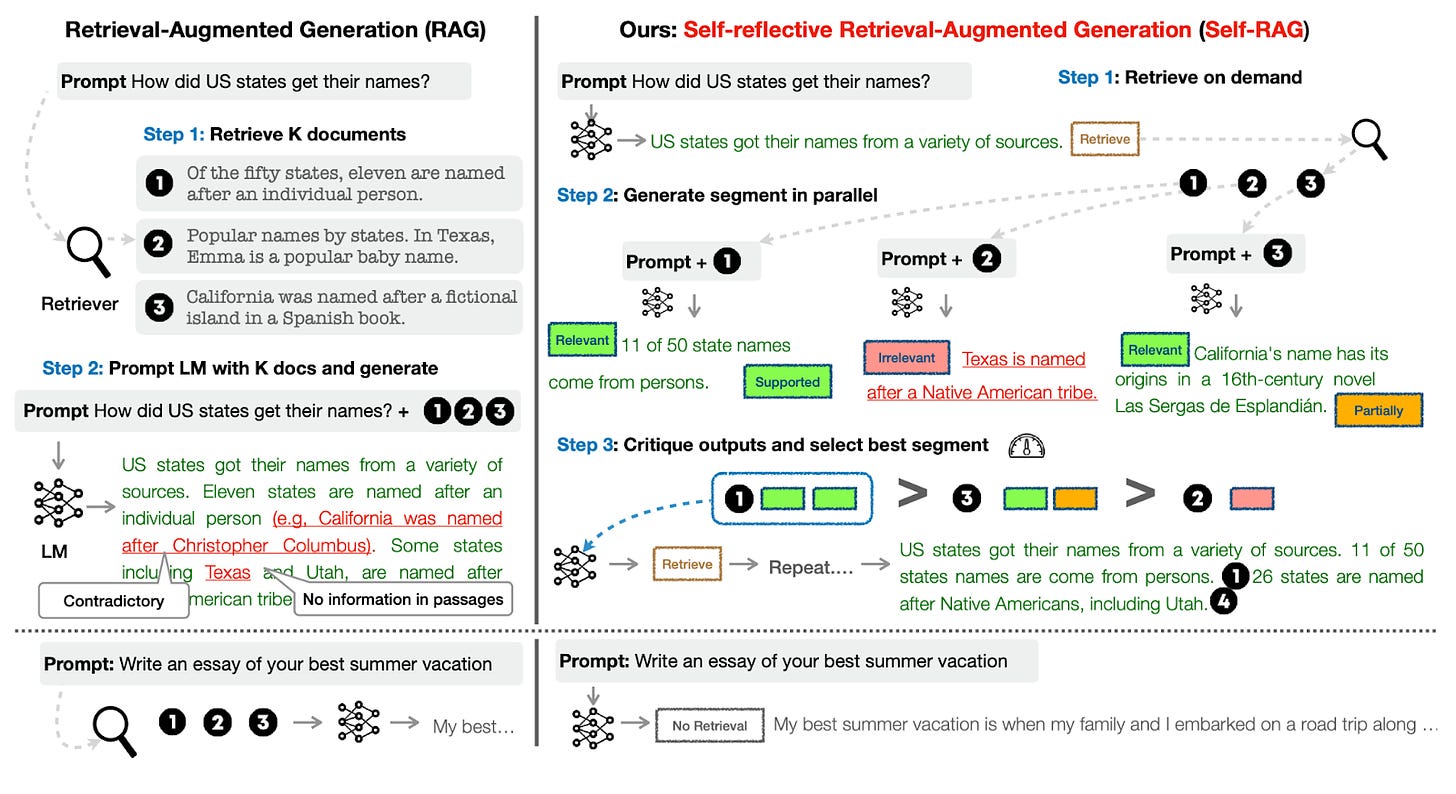
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- By Asai et al 2023
- The authors point out the problem with most RAG systems, which is that they retrieve passages indiscriminately regardless of whether the factual grounding is helpful.
- The Self-RAG algorithm uses a special type of token called a "reflection token" to communicate between the different parts of the algorithm: Retrieve, IsRel (relevance), IsSup (fully or not supporting), and IsUse (useful response).
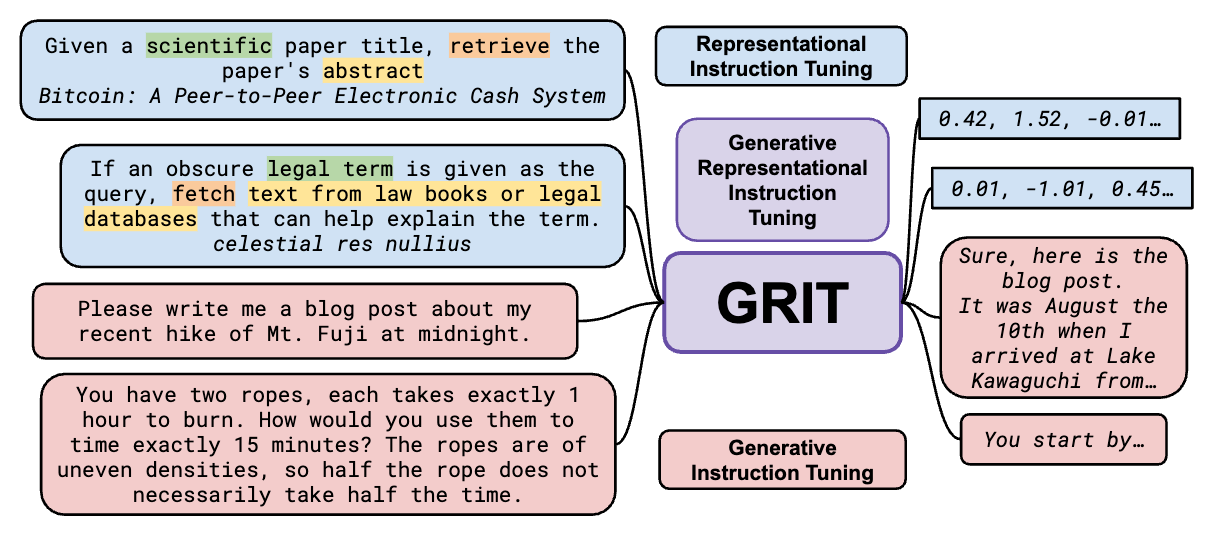
GRIT: Generative Representational Instruction Tuning
- By Muennighoff et al 2024
- GRIT addresses a similar problem to the above-mentioned paper while being very performant.
- The authors train a single LLM to perform both text generation and embedding tasks via Generative Instruction Tuning. In other words, the model architecture of GRITLM allows it to process input text, create embeddings, and generate output text.
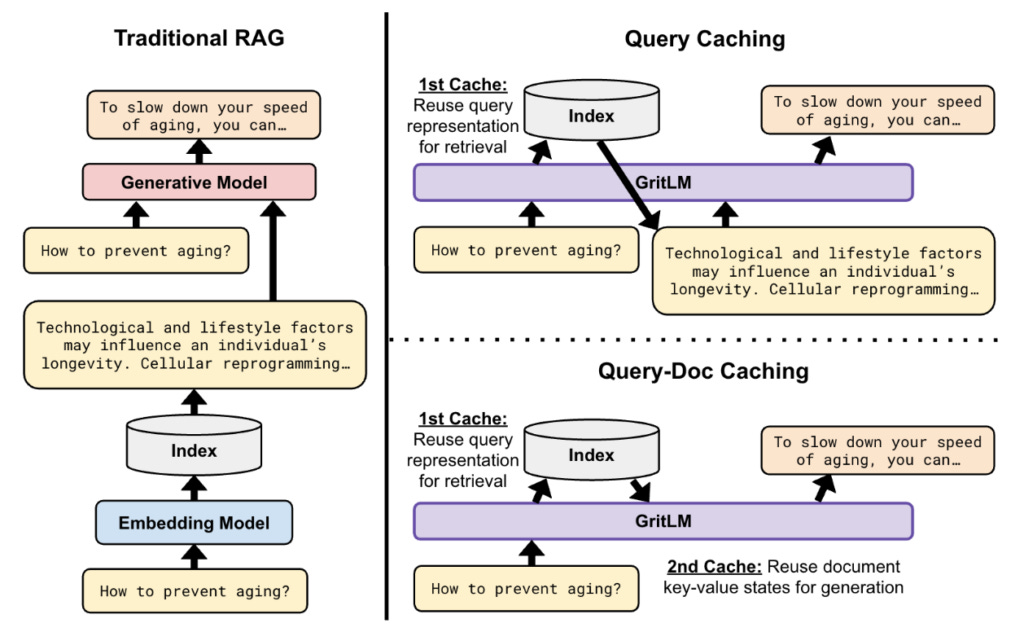
- Beyond the conditional tool use capability, performance is further enhanced by re-using:
- The query’s vector representations for retrieval and generation and
- Reusing the document key-value store (basically the raw retrieved vector db data) for generation.
- GRITLM sets a new benchmark by outperforming all generative models up to its size of 7 billion parameters, excelling in both generative and embedding tasks as demonstrated on the Massive Text Embedding Benchmark (MTEB) and various other evaluation benchmarks.
Conclusion
- All the products that some of us use daily, like Intercom.com’s AI chatbot, Perplexity.ai, You.com, phind.com, Komo.ai, or ChatGPT Browse with Bing, implement a frozen or less dynamic form of RAG.
- Much of the research summarized above lies dormant and has seen little application. It will be exciting to see companies commercializing secure and performant applications of this technology, enabling faster and more reliable access to knowledge.
Further Reading
Other summaries/literature reviews
- Retrieval-Augmented Generation (RAG): Paradigms, Technologies, and Trends By Presentation: Haofen Wang Tongji University
- Retrieval-Augmented Generation for Large Language Models: A Survey By Paper: Gao et al 2023
- Knowledge-Augmented Large Language Models with Personalized Knowledge Representation, Retrieval, Injection, and Verification By Research Statement: Baek
- Top Information Retrieval Papers of the Week By Substack Newsletter
- A Practitioners Guide to Retrieval Augmented Generation By Blog post
I plan to summarize more of these here when I find the time. If you think I’m missing a paper feel free to leave a comment or DM me about it:
Filtering and ranking
- Retrieving Texts based on Abstract Descriptions By Ravfogel et al 2023
- Retrieve to Explain: Evidence-driven Predictions with Language Models By Patel et al 2024 ⭐
- RAG-Fusion: a New Take on Retrieval-Augmented Generation By Rackauchas 2024
Transformer memory
- Memorizing Transformers By Wu et al 2022
- TRIME: Training Language Models with Memory Augmentation By Zhong et al 2022 ⭐
- Transformer Memory as a Differentiable Search Index By Tay et al 2022
Multi-modality
- Cross-Modal Retrieval Augmentation for Multi-Modal Classification By Gur et al 2021 ⭐
- Retrieval-Augmented Multimodal Language Modeling By Yasunaga et al 2022
- Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language By Berrios et al 2023
Knowledge Graphs & Reasoning
- Knowledge Guided Text Retrieval and Reading for Open Domain Question Answering By Min et al 2020
- UniK-QA: Unified Representations of Structured and Unstructured Knowledge for Open-Domain Question Answering By Oguz et al 2020
- Select and Augment: Enhanced Dense Retrieval Knowledge Graph Augmentation By Alfaifi and Alfaifi 2022
- Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval By Alon et al 2022
- Improving Wikipedia verifiability with AI By Petroni et al 2023
- KnowledGPT: Enhancing Large Language Models with Retrieval and Storage Access on Knowledge Bases (Wang et al 2023 ⭐
- Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation By Kang et al 2023
- G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering By He et al 2024
Other Reasoning Techniques
- StrategyQA: Question Answering Benchmark with Implicit Reasoning Strategies By Geva et al 2021
- Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval By Xiong et al 2021
- Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP By KhattaB et al 2022
- ASQA: Factoid Questions Meet Long-Form Answers By Stelmakh et al 2023
- SPRING: Studying the Paper and Reasoning to Play Games By Wu et al 2023 ⭐
- Do Large Language Models Latently Perform Multi-Hop Reasoning? By Yang et al 2024
Instruction & Memory
- Recitation-Augmented Language Models By Sun et al 2022
- InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining By Wang et al 2023
- RA-DIT: Retrieval-Augmented Dual Instruction Tuning By Lin, Chen, Chen et al 2023
- MemGPT: Towards LLMs as Operating Systems By Packer et al 2023 ⭐
- Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory By Cheng et al 2023
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models By Yu at al 2023