5 Levels of MLOps Maturity | by Maciej Balawejder | in Towards Data Science
Introduction
Building a solid infrastructure for ML systems is a big deal. It needs to ensure that the development and deployment of ML applications are organized and reliable. But here's the thing — every company's infrastructure needs are different. It depends on how many ML applications they have, how quickly they need to deploy, or how many requests they need to handle.
For example, if a company has just one model in production, the deployment process can be handled manually. On the other end of the spectrum, companies like Netflix or Uber, with hundreds of models in production, need highly specialized infrastructure to support them.
Now you might ask yourself a question : Where does your company fit on that spectrum?
MLOps maturity levels shared by Google and Microsoft are here to help. They describe the advancement and sophistication of the ML infrastructure based on the best practices in the industry.
This blog post aims to synthesize and take the best from both frameworks. First, we'll analyze five maturity levels and show the progression from manual processes to advanced automated infrastructures. Then, in the last section, we will argue that some of the points presented by Microsoft and Google should not be followed blindly but rather be adjusted to your needs. This should help you to be more aware in the process of figuring out where you stand with your infrastructure and finding potential areas for improvement.
Alright, let's dive in!
What is MLOps?
MLOps is a set of practices to establish a standardized and repeatable process for managing the entire ML lifecycle, starting from data preparation, model training, deployment, and monitoring. It borrows from the widely adopted DevOps practices in software engineering, which are focused on giving teams a rapid and continuously iterative approach to shipping software applications.
However, DevOps tools are not sufficient for the ML world and differ in several ways:
- MLOps requires a multidisciplinary team with a diverse skill set. This team includes data engineers responsible for data collection and storage, data scientists who develop the models, machine learning engineers(MLE) to deploy the models, and software engineers who integrate them with the product.
- Data science is inherently experimental, allowing for ongoing improvement by exploring different models, data analysis, training techniques, and hyperparameter configurations. The infrastructure supporting MLOps should include tracking and evaluating successful and unsuccessful approaches.
- Even if the model is up and running in production, it still can fail due to changes in the incoming data. This is called a silent model failure, caused by data and concept drift. Therefore, ML infrastructure requires a monitoring system to constantly check the model's performance and data to prevent this issue.
Now let's explore the various maturity levels of MLOps infrastructures.
Level 1 — Manual
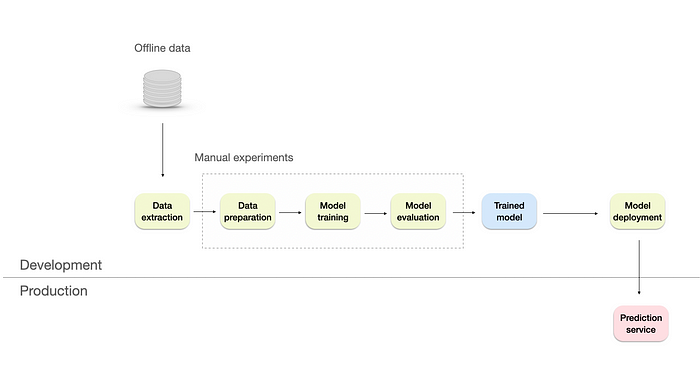
Manual ML infrastructure. The design is inspired by Google's blog post. Image by author.
At this level, the data processing, experimentation, and model deployment processes are entirely manual. Microsoft refers to this level as 'No MLOps', since the ML lifecycle is difficult to repeat and automate.
The entire workflow relies heavily on skilled data scientists, with some assistance from a data engineer to prepare the data and a software engineer to integrate the model with the product/business processes if needed.
This approach works great in cases like:
- Early-stage start-ups and proof of concept projects — where the focus is on experimentation and resources are limited. Developing and deploying ML models is the main concern before scaling up the operations.
- Small-scale ML applications — The manual approach can be sufficient for ML applications with limited scope or a small user base, like a small online fashion store. With minimal data dependencies and real-time requirements, data scientists can manually handle the data processing, experimentation, and deployment processes.
- Ad hoc ML tasks — In specific scenarios like marketing campaigns, one-time ML tasks or analyses may not require full MLOps implementation.
According to both Google and Microsoft, this approach also faces several limitations, including:
- Lack of monitoring system — there's no visibility on the model's performance. If it degrades, it will have a negative business impact. Also, there's post-deployment data science to understand the model's behavior in production.
- No frequent retrains of production models — no adaptation of the model to the latest trends or patterns.
- Releases are painful and infrequent — since it's done manually, releases of the models happen only a couple of times per year.
- No centralized tracking of model performance makes it hard to compare different models' performance, repeat the results, or update it.
- Limited documentation and no versioning — pose few challenges in terms of the risk of introducing unintended changes to the code, limited rollback to the working version, and lack of repeatability.
Level 2 — Repeatable
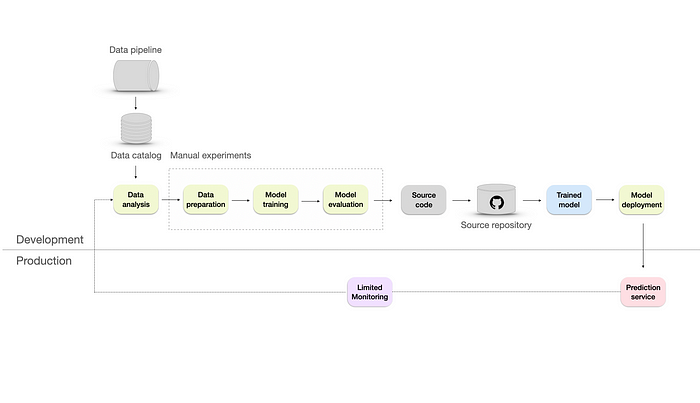
Repeatable ML infrastructure with additional source repository and monitoring. Image by author.
Next, we introduce the DevOps aspect to the infrastructure by converting the experiments to the source code and storing them in the source repository using a version control system like Git.
Microsoft suggests changes to the data collection process by adding the following:
- Data pipeline — allows to extract the data from different sources and combine them together. Then, the data is transformed using cleaning, aggregating, or filtering operations. It makes the infrastructure more scalable, efficient, and accurate than the manual one.
- Data catalog — a centralized repository that includes information such as data source, data type, data format, owner, usage, and lineage. It helps to organize, manage, and maintain large volumes of data in a scalable and efficient manner.
To level up the infrastructure, we must bring in some automated testing alongside version control. This means using practices like unit tests, integration tests, or regression tests. These will help us deploy faster and make things more reliable by ensuring our code changes don't cause errors or bugs.
With all those changes in place, we can repeat the data collection and deployment process. However, we still need a proper monitoring system. Microsoft mentions it briefly by saying there's "limited feedback on how well a model performs in production," but they don't go into the details about it.
Level 3 — Reproducible
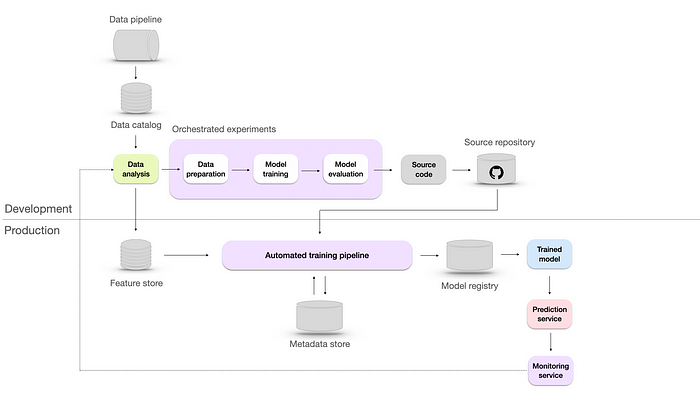
Reproducible ML infrastructure with automated training and orchestrated experiments. Image by author.
There are two key reasons why reproducibility is crucial: troubleshooting and collaboration. Imagine a scenario when the performance of your recently deployed model is deteriorating, resulting in inaccurate predictions. In that case, you need to keep a record of previous versions of the data and model to roll back the other version of the model until you find the root cause of the underlying issue.
Moreover, reproducibility makes it easier for different team members to understand what others are doing and build on each other's work. This collaborative approach and knowledge sharing can lead to faster innovation and better models.
To achieve reproducibility, we made have to level up the architecture in four ways:
- Automated training pipeline — handles the end-to-end process of training models, from data preparation to model evaluation.
- Metadata store — a database is a way to track and manage metadata, including data sources, model configurations, hyperparameters, training runs, evaluation metrics, and all the experiments data.
- Model registry — is a repository to store ML models, their versions, and their artifacts necessary for deployment, which helps to retrieve the exact version if needed.
- Feature store — which is there to help data scientists and machine learning engineers to develop, test, and deploy machine learning models more efficiently by providing a centralized location for storing, managing, and serving features. It also can be used to track the evolution of features over time and preprocess and transform features as needed.
At that stage, a monitoring service is available, offering real-time feedback on the performance of the model. However, apart from confirming it's there, neither Microsoft nor Google provide any additional information.
Level 4 — Automated
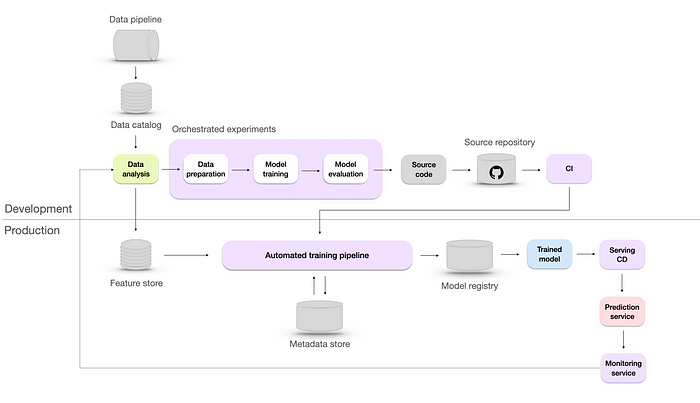
Automated ML infrastructure with CI/CD. Image by author.
This automation level helps data scientists efficiently explore new ideas in feature engineering, model architecture, and hyperparameters by automating the machine learning pipeline, including building, testing, and deployment. To achieve this, Microsoft suggests incorporating two extra components:
- CI/CD — where Continuous Integration (CI) ensures integration of code changes from different team members into a shared repository, while Continuous Deployment (CD) automates the deployment of validated code to production environments. This allows for rapid deployment of model updates, improvements, and bug fixes.
- A/B testing of models — this model validation method involves comparing predictions and user feedback between an existing model and a candidate model to determine the better one.
Level 5 — Continuously improved
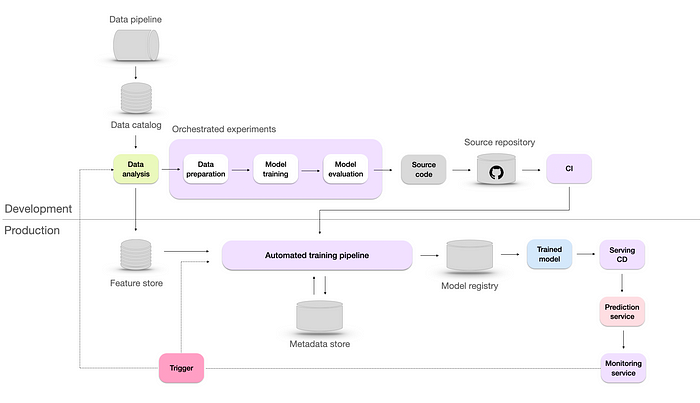
Continuously improved ML infrastructure with automated retraining. Image by author.
At this stage, the model is automatically retrained based on the trigger from the monitoring system. This process of retraining is also known as continuous learning. The objectives of continuous learning are:
- Combat sudden data drifts that may occur, ensuring the model remains effective even when faced with unexpected changes in the data.
- Adapt to rare events such as Black Friday, where patterns and trends in the data may significantly deviate from the norm.
- Overcoming the cold start problem, which arises when the model needs to make predictions for new users lacking historical data
Push for automation
Microsoft and Google are major players in the cloud computing market, with Azure holding a 22% market share and Google at 10%. They offer a wide range of services, including computing, storage, and development tools, which are essential components for building advanced ML infrastructure.
Like any business, they main goal is to generate revenue by selling these services. This is partially why their blogs emphasize advancement and automation. However, a higher level of maturity doesn't guarantee better results for your business. The optimal solution is the one that aligns with your company's specific needs and right tech stack.
While maturity levels can help to determine your current advancement, they shouldn't be followed blindly since Microsoft and Google's main incentives are to sell their services. The example is specifically their push for automated retraining. This process requires a lot of computation, but it's often unnecessary or harmful. Retraining should be done when needed. What's more important for your infrastructure is having a reliable monitoring system and an effective root cause analysis process.
Monitoring should start from the manual level
A limited monitoring system appears at level 2 in the described maturity levels. In reality, you should monitor your model as soon as business decisions are taken based on its output, regardless of maturity level. It allows you to reduce the risk of failure and see how the model performs regarding your business goals.
The initial step in monitoring can be as simple as comparing the model's predictions to the actual values. This basic comparison is a baseline assessment of the model's performance and a good starting point for further analysis when the model is failing. Additionally, it's important to consider the evaluation of data science efforts, which includes measuring the return on investment (ROI). This means assessing the value that data science techniques and algorithms bring to the table. It's crucial to understand how effective these efforts are in generating business value.
Evaluating ROI gives you insights and information that can help you make better decisions regarding allocating resources and planning future investments. As infrastructure evolves, the monitoring system can become more complex with additional features and capabilities. However, you should still pay attention to the importance of applying a basic monitoring setup to the infrastructure at the first level of maturity.
Risks of retraining
In the description of level 5, we listed the benefits of automatic retraining in production. However, before adding it to your infrastructure, you should consider the risks related to it:
- Retraining on delayed data
In some real-world scenarios, like loan-default prediction, labels may be delayed for months or even years. The ground truth is still coming, but you are retraining your model using the old data, which may not represent the current reality well.
2. Failure to determine the root cause of the problem
If the model's performance drops, it doesn't always mean that it needs more data. There could be various reasons for the model's failure, such as changes in downstream business processes, training-serving skew, or data leakage. You should first investigate to find the underlying issue and then retrain the model if necessary.
3. Higher risk of failure
Retraining amplifies the risk of model failure. Besides the fact that it adds complexity to the infrastructure, the more frequently you update, the more opportunities the model has to fail. Any undetected problem appearing in the data collection or preprocessing will be propagated to the model, resulting in a retrained model on flawed data.
4. Higher costs
Retraining is not a cost-free process. It involves expenses related to:
- Storing and validating the retraining data
- Compute resources to retrain the model
- Testing a new model to determine if it performs better than the current one
Summary
ML systems are complex. Building and deploying models in a repeatable and sustainable manner is tough. In this blog post, we have explored five MLOps maturity levels based on the Google and Microsoft best practices in the industry. We have discussed the evolution from manual deployment to automated infrastructures, highlighting the benefits that each level brings. However, it is crucial to understand that these practices should not be followed blindly. Instead, their adaptation should be based on your company's specific needs and requirements.
Source: https://towardsdatascience.com/5-levels-of-mlops-maturity-9c85adf09fe2